9.7.15.6. Asynchronous Warpgroup Level Multiply-and-Accumulate Operation using wgmma.mma_async.sp instruction
This section describes warp-level wgmma.mma_async.sp instruction with sparse matrix A. This variant of the wgmma.mma_async operation can be used when A is a structured sparse matrix with 50% zeros in each row distributed in a shape-specific granularity. For an MxNxK sparse wgmma.mma_async.sp operation, the MxK matrix A is packed into MxK/2 elements. For each K-wide row of matrix A, 50% elements are zeros and the remaining K/2 non-zero elements are packed in the operand representing matrix A. The mapping of these K/2 elements to the corresponding K-wide row is provided explicitly as metadata.
9.7.15.6.1. Sparse matrix storage
Granularity of sparse matrix A is defined as the ratio of the number of non-zero elements in a sub-chunk of the matrix row to the total number of elements in that sub-chunk where the size of the sub-chunk is shape-specific. For example, in a 64x32 matrix A used in floating point wgmma.mma_async operations, sparsity is expected to be at 2:4 granularity, i.e. each 4-element vector (i.e. a sub-chunk of 4 consecutive elements) of a matrix row contains 2 zeros. Index of each non-zero element in a sub-chunk is stored in the metadata operand. Values 0b0000, 0b0101, 0b1010, 0b1111 are invalid values for metadata and will result in undefined behavior. In a group of four consecutive threads, one or more threads store the metadata for the whole group depending upon the matrix shape. These threads are specified using an additional sparsity selector operand.
Matrix A and its corresponding input operand to the sparse wgmma is similar to the diagram shown in Figure 111, with an appropriate matrix size.
Granularities for different matrix shapes and data types are described below.
Sparse wgmma.mma_async.sp with half-precision and .bf16 type
For .f16 and .bf16 types, for all supported 64xNx32 shapes, matrix A is structured sparse at a granularity of 2:4. In other words, each chunk of four adjacent elements in a row of matrix A have two zeroes and two non-zero elements. Only the two non-zero elements are stored in matrix A and their positions in the four-wide chunk in Matrix A are indicated by two 2-bits indices in the metadata operand.
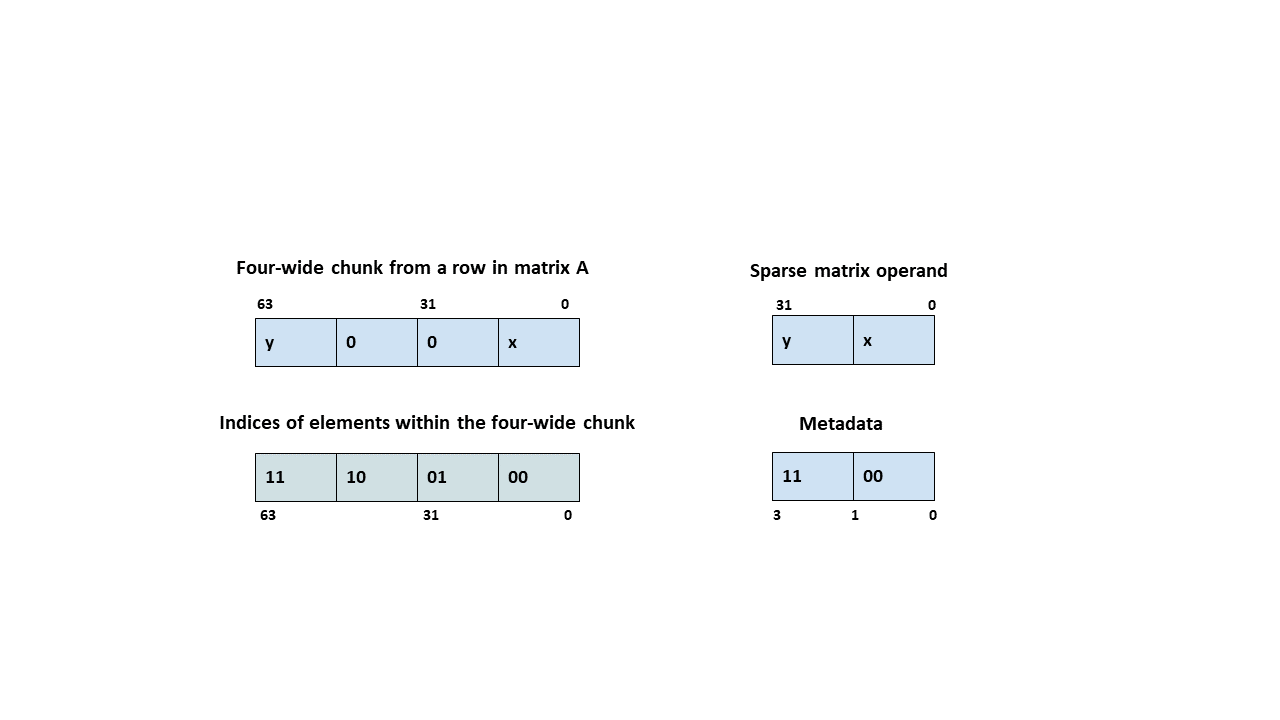
Figure 171 Sparse WGMMA metadata example for .f16/.bf16 type.
The sparsity selector indicates a thread-pair within a group of four consecutive threads which contributes the sparsity metadata. Hence, the sparsity selector must be either 0 (threads T0, T1) or 1 (threads T2, T3); any other value results in an undefined behavior.
Sparse wgmma.mma_async.sp with .tf32 type
For .tf32 type, for all supported 64xNx16 shapes, matrix A is structured sparse at a granularity of 1:2. In other words, each chunk of two adjacent elements in a row of matrix A have one zero and one non-zero element. Only the non-zero element is stored in operand for matrix A and the 4-bit index in the metadata indicates the position of the non-zero element in the two-wide chunk. 0b1110 and 0b0100 are the only meaningful values of the index, the remaining values result in an undefined behavior.
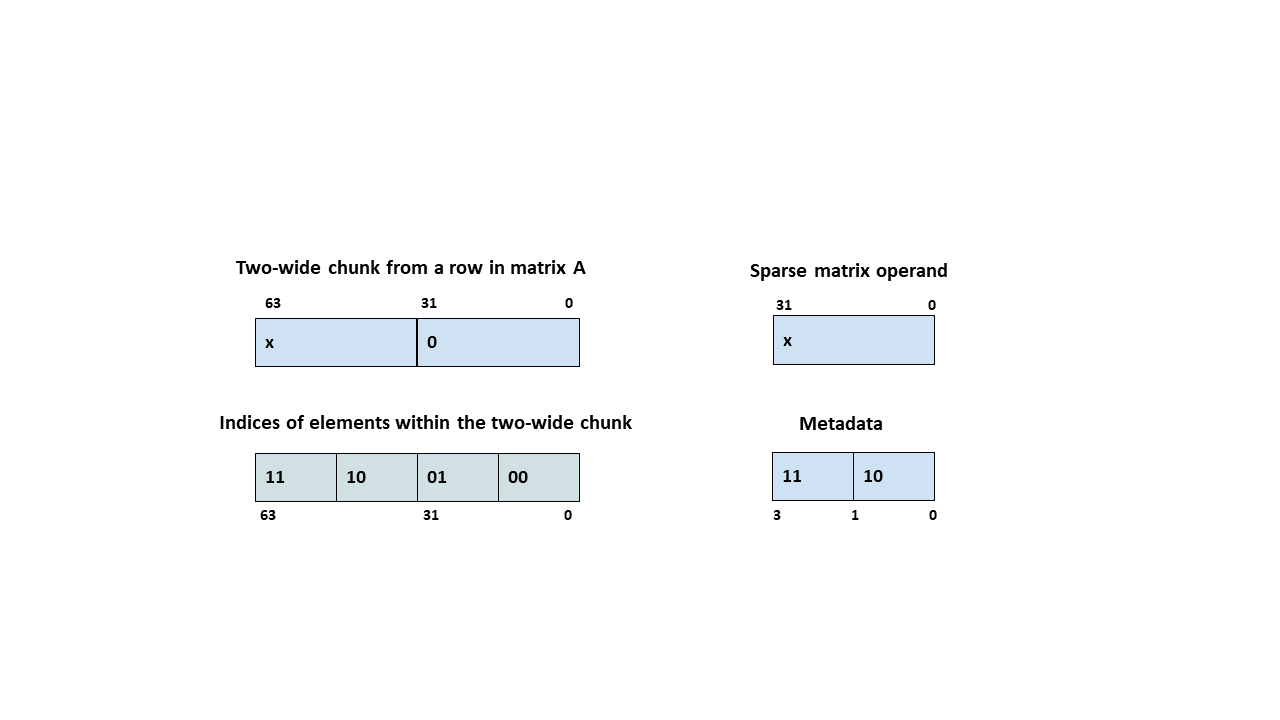
Figure 172 Sparse WGMMA metadata example for .tf32 type.
The sparsity selector indicates a thread-pair within a group of four consecutive threads which contributes the sparsity metadata. Hence, the sparsity selector must be either 0 (threads T0, T1) or 1 (threads T2, T3); any other value results in an undefined behavior.
Sparse wgmma.mma_async.sp with .e4m3 and .e5m2 floating point type
For .e4m3 and .e5m2 types, for all supported 64xNx64 shapes, matrix A is structured sparse at a granularity of 2:4. In other words, each chunk of four adjacent elements in a row of matrix A have two zeroes and two non-zero elements. Only the two non-zero elements are stored in matrix A and their positions in the four-wide chunk in Matrix A are indicated by two 2-bits indices in the metadata operand.
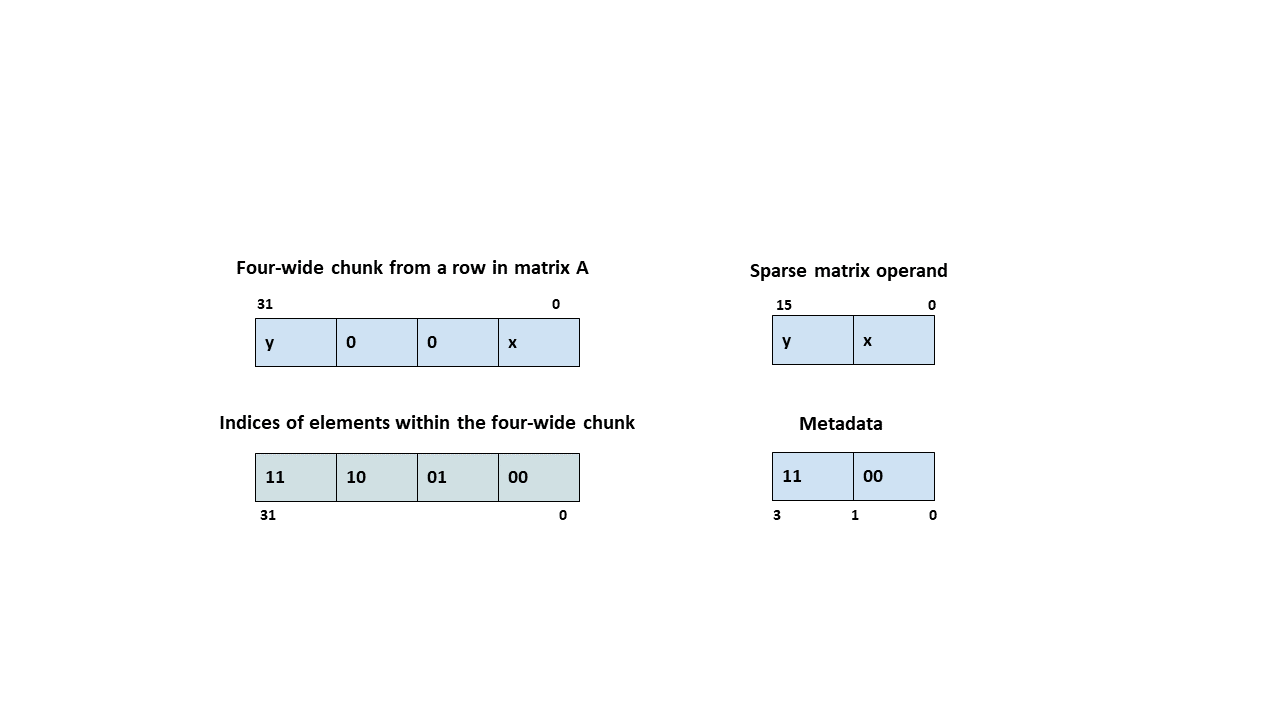
Figure 173 Sparse WGMMA metadata example for .e4m3/.e5m2 type.
All threads contribute the sparsity metadata and the sparsity selector must be 0; any other value results in an undefined behavior.
Sparse wgmma.mma_async.sp with integer type
For the integer type, for all supported 64xNx64 shapes, matrix A is structured sparse at a granularity of 2:4. In other words, each chunk of four adjacent elements in a row of matrix A have two zeroes and two non-zero elements. Only the two non-zero elements are stored in matrix A and two 2-bit indices in the metadata indicate the position of these two non-zero elements in the four-wide chunk.
Figure 174 Sparse WGMMA metadata example for .u8/.s8 type.
All threads contribute the sparsity metadata and the sparsity selector must be 0; any other value results in an undefined behavior.
9.7.15.6.2. Matrix fragments for warpgroup-level multiply-accumulate operation with sparse matrix A
In this section we describe how the contents of thread registers are associated with fragments of A matrix and the sparsity metadata.
Each warp in the warpgroup provides sparsity information for 16 rows of matrix A. The following table shows the assignment of warps to rows of matrix A:
| Warp | Sparsity information for rows of matrix A |
|---|---|
%warpid % 4 = 3 |
48-63 |
%warpid % 4 = 2 |
32-47 |
%warpid % 4 = 1 |
16-31 |
%warpid % 4 = 0 |
0-15 |
The following conventions are used throughout this section:
- For matrix A, only the layout of a fragment is described in terms of register vector sizes and their association with the matrix data.
- For matrix D, since the matrix dimension - data type combination is the same for all supported shapes, and is already covered in Asynchronous Warpgroup Level Matrix Multiply-Accumulate Operation using wgmma.mma_async instruction, the pictorial representations of matrix fragments are not included in this section.
- For the metadata operand, pictorial representations of the association between indices of the elements of matrix A and the contents of the metadata operand are included.
Tk: [m..n]present in cell[x][y..z]indicates that bits m through n (with m being higher) in the metadata operand of thread with%laneid=kcontains the indices of the non-zero elements from the chunk[x][y]..[x][z]of matrix A.
9.7.15.6.2.1. Matrix Fragments for sparse wgmma.mma_async.m64nNk32
A warpgroup executing sparse wgmma.mma_async.m64nNk32 will compute an MMA operation of shape .m64nNk32 where N is a valid n dimension as listed in Matrix Shape.
Elements of the matrix are distributed across the threads in a warpgroup so each thread of the warpgroup holds a fragment of the matrix.
Multiplicand A, from shared memory is documented in Shared Memory Matrix Layout.
Multiplicand A, from registers:
.atype |
Fragments | Elements |
|---|---|---|
.f16 / .bf16 |
A vector expression containing four .b32 registers, with each register containing two non-zero .f16 /.bf16 elements out of 4 consecutive elements from matrix A. |
Non-zero elements: a0, a1, a2, a3, a4, a5, a6, a7. Mapping of the non-zero elements is as described in Sparse matrix storage. |
The layout of the fragments held by different threads is shown in Figure 175.

Figure 175 Sparse WGMMA .m64nNk32 fragment layout for matrix A with .f16/.bf16 type.
Accumulator D:
Matrix fragments for accumulator D are the same as in case of Matrix Fragments for wgmma.mma_async.m64nNk32 for the same .dtype format.
Multiplicand B:
Shared memory layout for Matrix B is documented in Shared Memory Matrix Layout.
Metadata operand is a .b32 register containing 16 2-bit vectors each storing the index of a non-zero element of a 4-wide chunk of matrix A.
Figure 176 shows the mapping of the metadata bits to the elements of matrix A for a warp. In this figure, variable i represents the value of the sparsity selector operand.
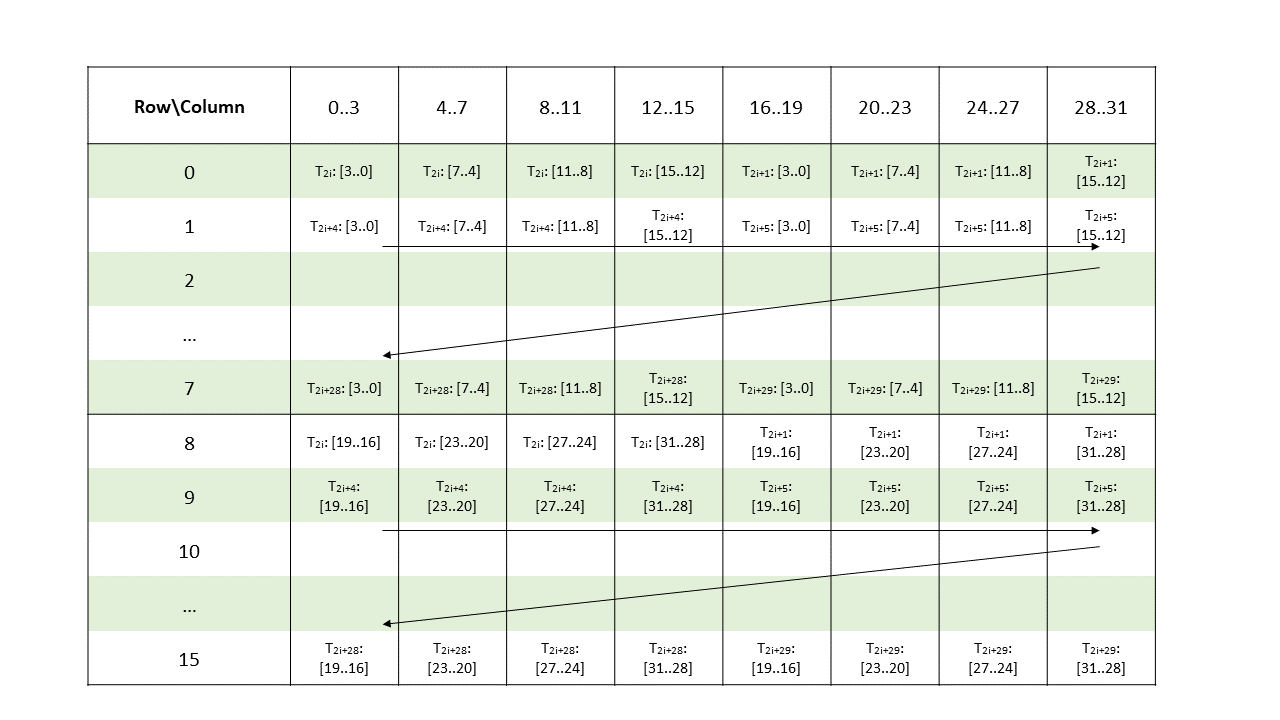
Figure 176 Sparse WGMMA .m64nNk32 metadata layout for .f16/.bf16 type.
9.7.15.6.2.2. Matrix Fragments for sparse wgmma.mma_async.m64nNk16
A warpgroup executing sparse wgmma.mma_async.m64nNk16 will compute an MMA operation of shape .m64nNk16 where N is a valid n dimension as listed in Matrix Shape.
Elements of the matrix are distributed across the threads in a warpgroup so each thread of the warpgroup holds a fragment of the matrix.
Multiplicand A, from shared memory is documented in Shared Memory Matrix Layout.
Multiplicand A, from registers:
.atype |
Fragments | Elements |
|---|---|---|
.tf32 |
A vector expression containing four .b32 registers, containing four non-zero .tf32 elements out of eight consecutive elements from matrix A. |
Non-zero elements: a0, a1, a2, a3. Mapping of the non-zero elements is as described in Sparse matrix storage. |
The layout of the fragments held by different threads is shown in Figure 177.
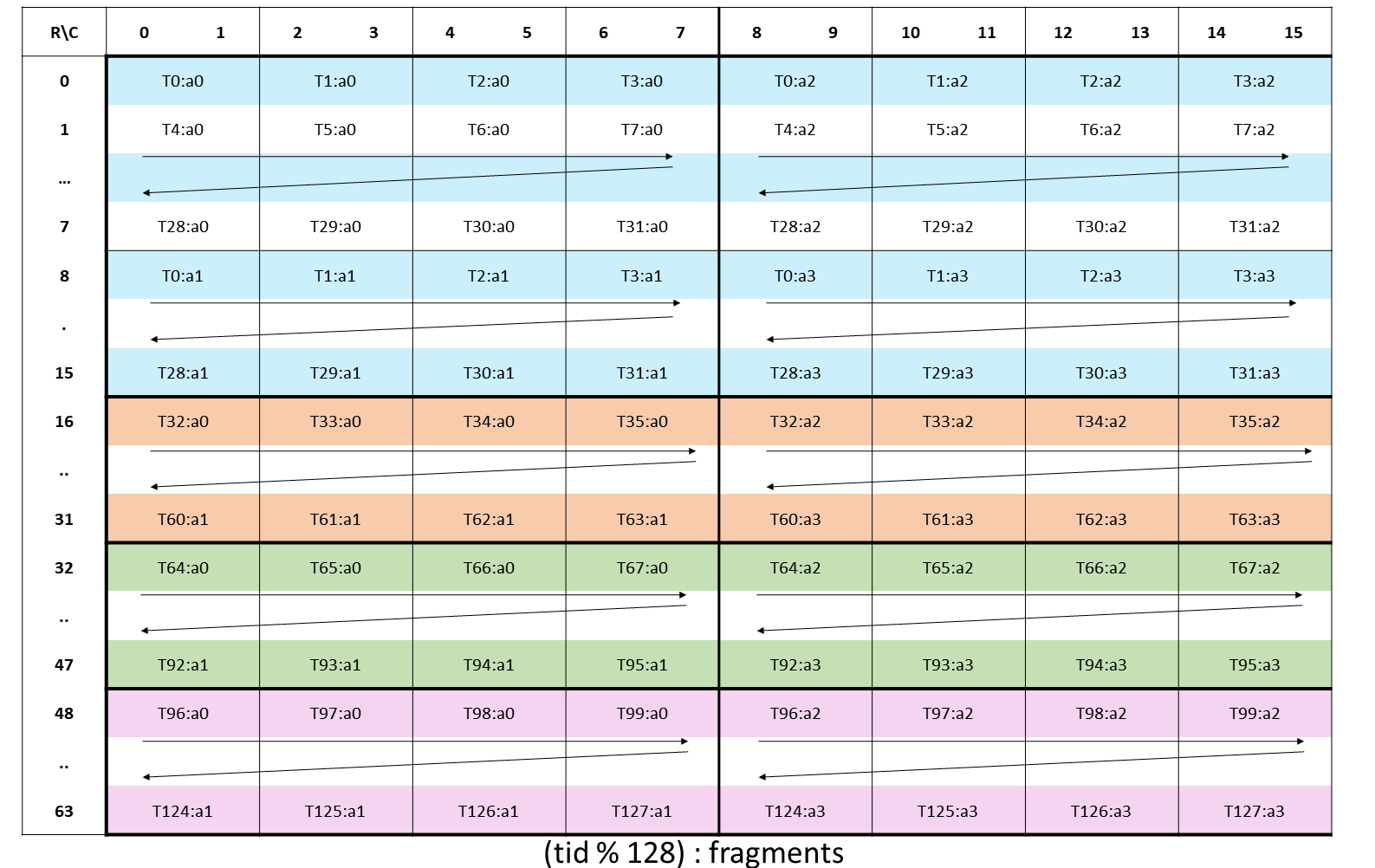
Figure 177 Sparse WGMMA .m64nNk16 fragment layout for matrix A with .tf32 type.
Accumulator D:
Matrix fragments for accumulator D are the same as in case of Matrix Fragments for wgmma.mma_async.m64nNk8 for the same .dtype format.
Multiplicand B:
Shared memory layout for Matrix B is documented in Shared Memory Matrix Layout.
Metadata operand is a .b32 register containing eight 4-bit vectors each storing the index of a non-zero element of a 2-wide chunk of matrix A.
Figure 178 shows the mapping of the metadata bits to the elements of matrix A for a warp. In this figure, variable i represents the value of the sparsity selector operand.
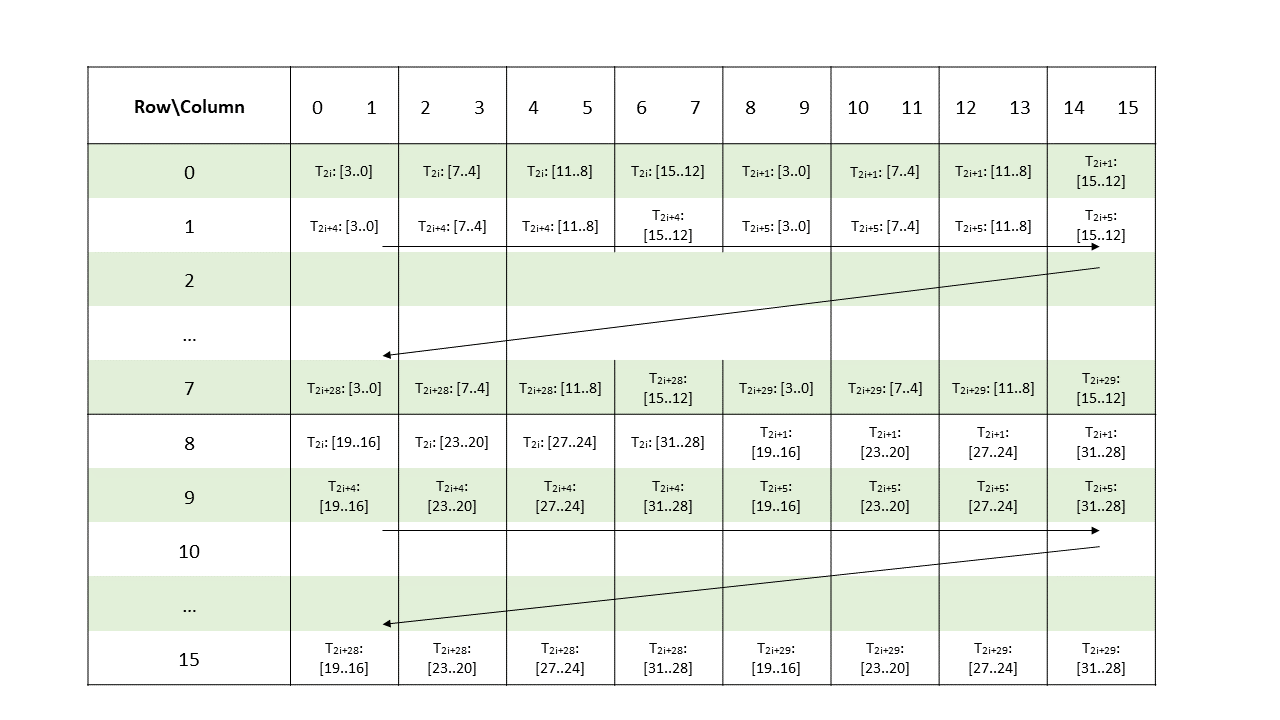
Figure 178 Sparse WGMMA .m64nNk16 metadata layout for .tf32 type.
9.7.15.6.2.3. Matrix Fragments for sparse wgmma.mma_async.m64nNk64
A warpgroup executing sparse wgmma.mma_async.m64nNk64 will compute an MMA operation of shape .m64nNk64 where N is a valid n dimension as listed in Matrix Shape.
Elements of the matrix are distributed across the threads in a warpgroup so each thread of the warpgroup holds a fragment of the matrix.
Multiplicand A, from shared memory is documented in Matrix Fragments for sparse wgmma.mma_async.m64nNk64.
Multiplicand A, from registers:
.atype |
Fragments | Elements |
|---|---|---|
.e4m3 / .e5m2 |
A vector expression containing four .b32 registers, with each register containing four non-zero .e4m3 /.e5m2 elements out of eight consecutive elements from matrix A. |
Non-zero elements: a0, a1, a2, … , a15. Mapping of the non-zero elements is as described in Sparse matrix storage. |
.s8 / .u8 |
A vector expression containing four .b32 registers, with each register containing four non-zero .s8 /.u8 elements out of eight consecutive elements from matrix A. |
The layout of the fragments held by different threads is shown in Figure 179.
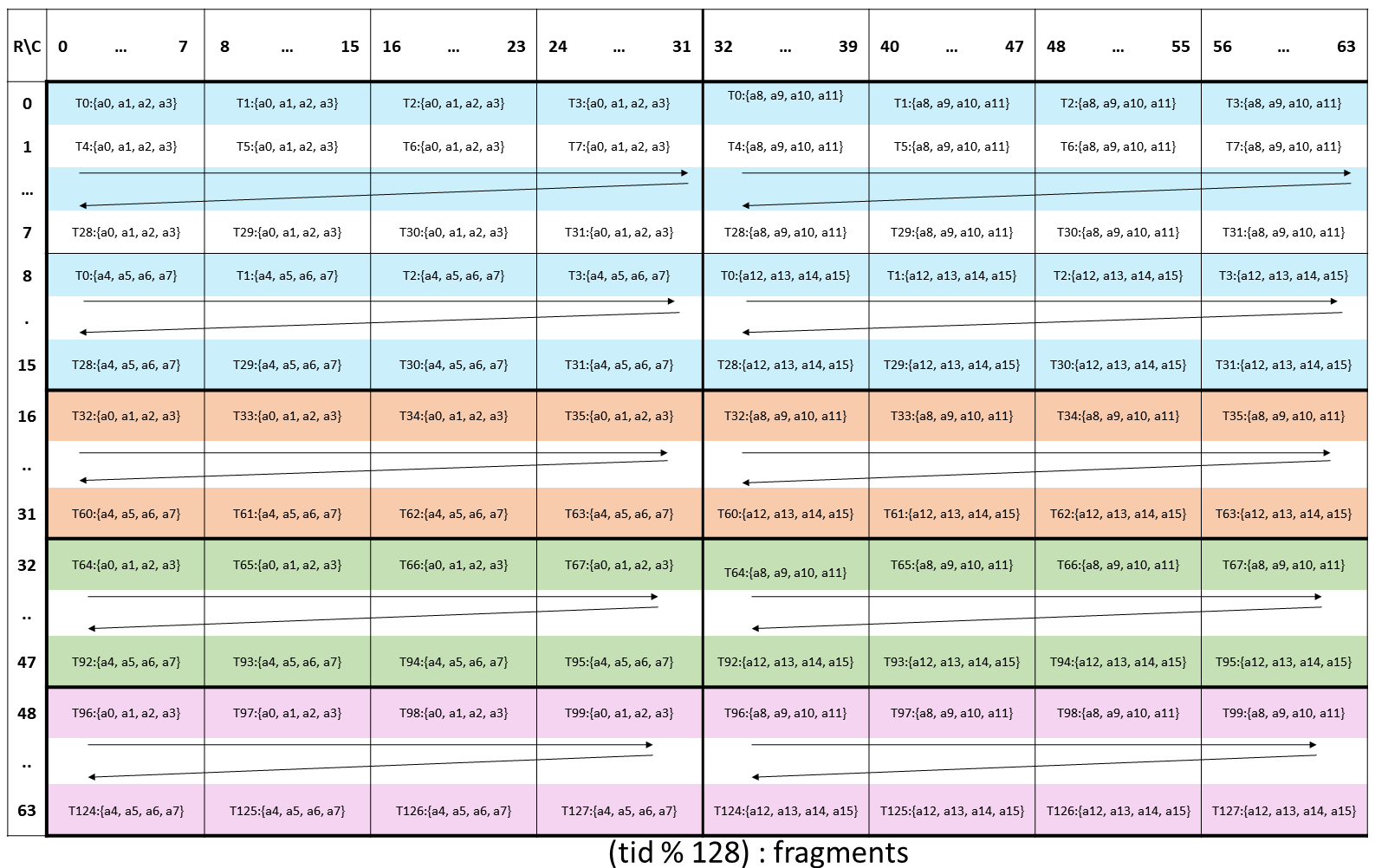
Figure 179 Sparse WGMMA .m64nNk64 fragment layout for matrix A with .e4m3/ .e5m2/ .s8/ .u8 type.
Accumulator D:
Matrix fragments for accumulator D are the same as in case of Matrix Fragments for wgmma.mma_async.m64nNk32 for the same .dtype format.
Multiplicand B:
Shared memory layout for Matrix B is documented in Matrix Fragments for sparse wgmma.mma_async.m64nNk64.
Metadata operand is a .b32 register containing 16 4-bit vectors each storing the indices of two non-zero elements of a 4-wide chunk of matrix A.
Figure 180 shows the mapping of the metadata bits to the elements of columns 0–31 of matrix A.
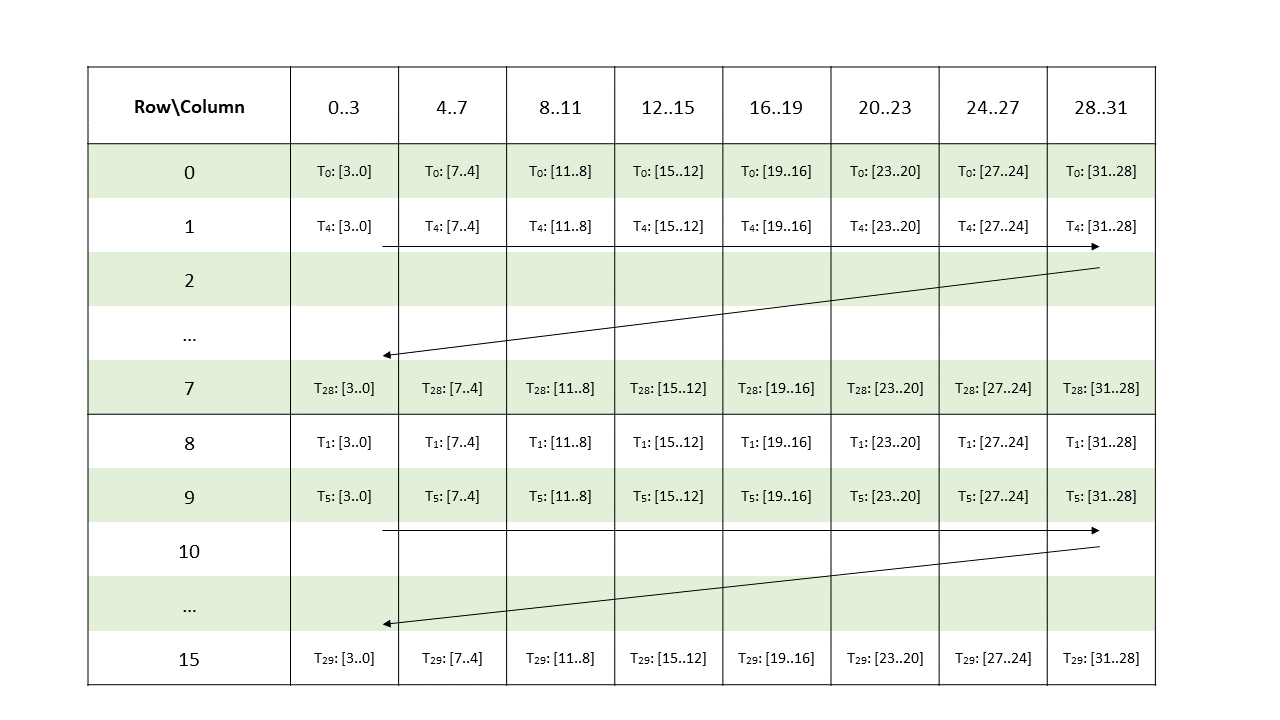
Figure 180 Sparse WGMMA .m64nNk64 metadata layout for .e4m3/ .e5m2/ .s8/ .u8 type for columns 0–31
Figure 181 shows the mapping of the metadata bits to the elements of columns 32–63 of matrix A.
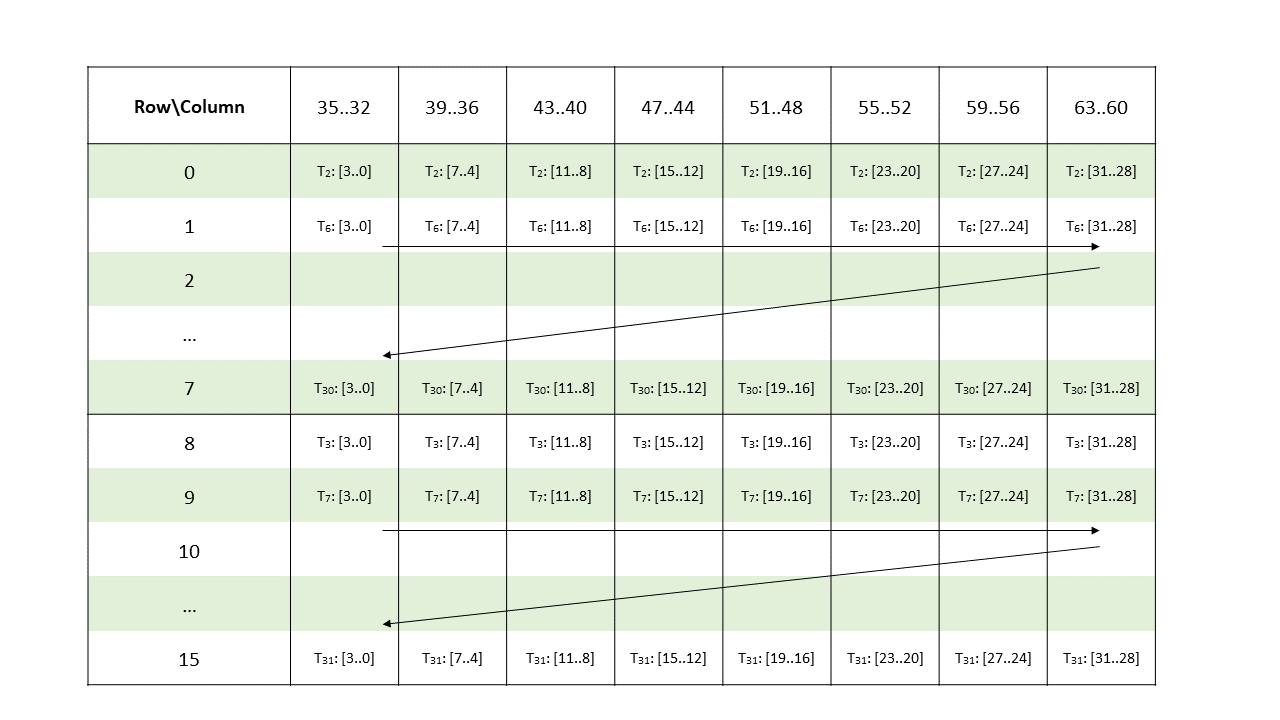
Figure 181 Sparse WGMMA .m64nNk64 metadata layout for .e4m3/ .e5m2/ .s8/ .u8 type for columns 32–63
9.7.15.6.3. Asynchronous Multiply-and-Accumulate Instruction: wgmma.mma_async.sp
wgmma.mma_async.sp
Perform matrix multiply-and-accumulate operation with sparse matrix A across warpgroup
Syntax
Half precision floating point type:
wgmma.mma_async.sp.sync.aligned.shape.dtype.f16.f16 d, a-desc, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b, imm-trans-a, imm-trans-b;
wgmma.mma_async.sp.sync.aligned.shape.dtype.f16.f16 d, a, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b, imm-trans-b;.shape = {.m64n8k32, .m64n16k32, .m64n24k32, .m64n32k32,
.m64n40k32, .m64n48k32, .m64n56k32, .m64n64k32,
.m64n72k32, .m64n80k32, .m64n88k32, .m64n96k32,
.m64n104k32, .m64n112k32, .m64n120k32, .m64n128k32,
.m64n136k32, .m64n144k32, .m64n152k32, .m64n160k32,
.m64n168k32, .m64n176k32, .m64n184k32, .m64n192k32,
.m64n200k32, .m64n208k32, .m64n216k32, .m64n224k32,
.m64n232k32, .m64n240k32, .m64n248k32, .m64n256k32};
.dtype = {.f16, .f32};Alternate floating point type:
.bf16 floating point type:
wgmma.mma_async.sp.sync.aligned.shape.dtype.bf16.bf16 d, a-desc, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b, imm-trans-a, imm-trans-b;
wgmma.mma_async.sp.sync.aligned.shape.dtype.bf16.bf16 d, a, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b, imm-trans-b;.shape = {.m64n8k32, .m64n16k32, .m64n24k32, .m64n32k32,
.m64n40k32, .m64n48k32, .m64n56k32, .m64n64k32,
.m64n72k32, .m64n80k32, .m64n88k32, .m64n96k32,
.m64n104k32, .m64n112k32, .m64n120k32, .m64n128k32,
.m64n136k32, .m64n144k32, .m64n152k32, .m64n160k32,
.m64n168k32, .m64n176k32, .m64n184k32, .m64n192k32,
.m64n200k32, .m64n208k32, .m64n216k32, .m64n224k32,
.m64n232k32, .m64n240k32, .m64n248k32, .m64n256k32};
.dtype = {.f32};.tf32 floating point type:
wgmma.mma_async.sp.sync.aligned.shape.dtype.tf32.tf32 d, a-desc, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b;
wgmma.mma_async.sp.sync.aligned.shape.dtype.tf32.tf32 d, a, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b;.shape = {.m64n8k16, .m64n16k16, .m64n24k16, .m64n32k16,
.m64n40k16, .m64n48k16, .m64n56k16, .m64n64k16,
.m64n72k16, .m64n80k16, .m64n88k16, .m64n96k16,
.m64n104k16, .m64n112k16, .m64n120k16, .m64n128k16,
.m64n136k16, .m64n144k16, .m64n152k16, .m64n160k16,
.m64n168k16, .m64n176k16, .m64n184k16, .m64n192k16,
.m64n200k16, .m64n208k16, .m64n216k16, .m64n224k16,
.m64n232k16, .m64n240k16, .m64n248k16, .m64n256k16};
.dtype = {.f32};FP8 floating point type:
wgmma.mma_async.sp.sync.aligned.shape.dtype.atype.btype d, a-desc, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b;
wgmma.mma_async.sp.sync.aligned.shape.dtype.atype.btype d, a, b-desc, sp-meta, sp-sel, scale-d, imm-scale-a, imm-scale-b;.shape = {.m64n8k64, .m64n16k64, .m64n24k64, .m64n32k64,
.m64n40k64, .m64n48k64, .m64n56k64, .m64n64k64,
.m64n72k64, .m64n80k64, .m64n88k64, .m64n96k64,
.m64n104k64, .m64n112k64, .m64n120k64, .m64n128k64,
.m64n136k64, .m64n144k64, .m64n152k64, .m64n160k64,
.m64n168k64, .m64n176k64, .m64n184k64, .m64n192k64,
.m64n200k64, .m64n208k64, .m64n216k64, .m64n224k64,
.m64n232k64, .m64n240k64, .m64n248k64, .m64n256k64};
.atype = {.e4m3, .e5m2};
.btype = {.e4m3, .e5m2};
.dtype = {.f16, .f32};Integer type:
wgmma.mma_async.sp.sync.aligned.shape{.satfinite}.s32.atype.btype d, a-desc, b-desc, sp-meta, sp-sel, scale-d;
wgmma.mma_async.sp.sync.aligned.shape{.satfinite}.s32.atype.btype d, a, b-desc, sp-meta, sp-sel, scale-d;.shape = {.m64n8k64, .m64n16k64, .m64n24k64, .m64n32k64,
.m64n48k64, .m64n64k64, .m64n80k64, .m64n96k64,
.m64n112k64, .m64n128k64, .m64n144k64, .m64n160k64,
.m64n176k64, .m64n192k64, .m64n208k64, .m64n224k64,
.m64n240k64, .m64n256k64};
.atype = {.s8, .u8};
.btype = {.s8, .u8};Description
Instruction wgmma.mma_async issues a MxNxK matrix multiply and accumulate operation, D = A\*B+D, where the A matrix is MxK, the B matrix is KxN, and the D matrix is MxN.
The matrix A is stored in the packed format Mx(K/2) as described in Sparse matrix storage.
The operation of the form D = A\*B is issued when the input predicate argument scale-d is false.
wgmma.fence instruction must be used to fence the register accesses of wgmma.mma_async instruction from their prior accesses. Otherwise, the behavior is undefined.
wgmma.commit_group and wgmma.wait_group operations must be used to wait for the completion of the asynchronous matrix multiply and accumulate operations before the results are accessed.
Register operand d represents the accumulator matrix as well as the destination matrix, distributed across the participating threads. Register operand a represents the multiplicand matrix A in register distributed across the participating threads. The 64-bit register operands a-desc and b-desc are the matrix descriptors which represent the multiplicand matrices A and B in shared memory respectively. The contents of a matrix descriptor must be same across all the warps in the warpgroup. The format of the matrix descriptor is described in Matrix Descriptor Format. Matrix A is structured sparse as described in Sparse matrix storage. Operands sp-meta and sp-sel represent sparsity metadata and sparsity selector respectively. Operand sp-meta is a 32-bit integer and operand sp-sel is a 32-bit integer constant with values in the range 0..3.
The valid values of sp-meta and sp-sel for each shape is specified in Sparse matrix storage and are summarized here:
| Matrix shape | .atype |
Valid values of sp-meta | Valid values of sp-sel |
|---|---|---|---|
.m64nNk16 |
.tf32 |
0b1110, 0b0100 |
0 (threads T0, T1) or 1 (threads T2, T3) |
.m64nNk32 |
.f16/ .bf16 |
0b00, 0b01, 0b10, 0b11 |
0 (threads T0, T1) or 1 (threads T2, T3) |
.m64nNk64 |
.e4m3 / .e5m2 / .s8 / .u8 |
0b00, 0b01, 0b10, 0b11 |
0 (all threads contribute) |
Matrices A and B are stored in row-major and column-major format respectively. For certain floating point variants, the input matrices A and B can be transposed by specifying the value 1 for the immediate integer arguments imm-trans-a and imm-trans-b respectively. A value of 0 can be used to avoid the transpose operation. The valid values of imm-trans-a and imm-trans-b are 0 and 1. The transpose operation is only supported for the wgmma.mma_async variants with .f16/ .bf16 types on matrices accessed from shared memory using matrix descriptors.
For the floating point variants of the wgmma.mma_async operation, each element of the input matrices A and B can be negated by specifying the value -1 for operands imm-scale-a and imm-scale-b respectively. A value of 1 can be used to avoid the negate operation. The valid values of imm-scale-a and imm-scale-b are -1 and 1.
The qualifiers .dtype, .atype and .btype indicate the data type of the elements in matrices D, A and B respectively. .atype and .btype must be the same for all floating point wgmma.mma_async variants except for the FP8 floating point variants. The sizes of individual data elements of matrices A and B in alternate floating point variants of the wgmma.mma_async operation are as follows:
- Matrices A and B have 8-bit data elements when
.atype/.btypeis.e4m3/.e5m2. - Matrices A and B have 16-bit data elements when
.atype/.btypeis.bf16. - Matrices A and B have 32-bit data elements when
.atype/.btypeis.tf32.
Precision and rounding:
Floating point operations:
Element-wise multiplication of matrix A and B is performed with at least single precision. When .dtype is .f32, accumulation of the intermediate values is performed with at least single precision. When .dtype is .f16, the accumulation is performed with at least half precision.
The accumulation order, rounding and handling of subnormal inputs are unspecified.
.bf16 and .tf32 floating point operations:
Element-wise multiplication of matrix A and B is performed with specified precision. wgmma.mma_async operation involving type .tf32 will truncate lower 13 bits of the 32-bit input data before multiplication is issued. Accumulation of the intermediate values is performed with at least single precision.
The accumulation order, rounding, and handling of subnormal inputs are unspecified.
Integer operations:
The integer wgmma.mma_async operation is performed with .s32 accumulators. The .satfinite qualifier indicates that on overflow, the accumulated value is limited to the range MIN_INT32.. MAX_INT32 (where the bounds are defined as the minimum negative signed 32-bit integer and the maximum positive signed 32-bit integer respectively).
If .satfinite is not specified, the accumulated value is wrapped instead.
The mandatory .sync qualifier indicates that wgmma.mma_async instruction causes the executing thread to wait until all threads in the warp execute the same wgmma.mma_async instruction before resuming execution.
The mandatory .aligned qualifier indicates that all threads in the warpgroup must execute the same wgmma.mma_async instruction. In conditionally executed code, a wgmma.mma_async instruction should only be used if it is known that all threads in the warpgroup evaluate the condition identically, otherwise behavior is undefined.
PTX ISA Notes
Introduced in PTX ISA version 8.2.
Support for .u8.s8 and .s8.u8 as .atype.btype introduced in PTX ISA version 8.4.
Target ISA Notes
Requires sm_90a.
Examples
Examples of integer type:
wgmma.fence.sync.aligned;
wgmma.mma_async.sp.sync.aligned.m64n8k64.s32.u8.u8 {s32d0, s32d1, s32d2, s32d3},
descA, descB, spMeta, 0, scaleD;
wgmma.mma_async.sp.sync.aligned.m64n8k64.s32.s8.u8 {s32d0, s32d1, s32d2, s32d3},
descA, descB, spMeta, 0, scaleD;
wgmma.commit_group.sync.aligned;
wgmma.wait_group.sync.aligned 0;