9.7.14.5.17. Warp-level matrix transpose instruction: movmatrix
movmatrix
Transpose a matrix in registers across the warp.
Syntax
movmatrix.sync.aligned.shape.trans.type d, a;
.shape = {.m8n8};
.type = {.b16};Description
Move a row-major matrix across all threads in a warp, reading elements from source a, and writing the transposed elements to destination d.
The .shape qualifier indicates the dimensions of the matrix being transposed. Each matrix element holds 16-bit data as indicated by the .type qualifier.
The mandatory .sync qualifier indicates that movmatrix causes the executing thread to wait until all threads in the warp execute the same movmatrix instruction before resuming execution.
The mandatory .aligned qualifier indicates that all threads in the warp must execute the same movmatrix instruction. In conditionally executed code, a movmatrix instruction should only be used if it is known that all threads in the warp evaluate the condition identically, otherwise the behavior is undefined.
Operands a and d are 32-bit registers containing fragments of the input matrix and the resulting matrix respectively. The mandatory qualifier .trans indicates that the resulting matrix in d is a transpose of the input matrix specified by a.
Each thread in a warp holds a fragment of a row of the input matrix, with thread 0 holding the first fragment in register a, and so on. A group of four threads holds an entire row of the input matrix as shown in Figure 109.
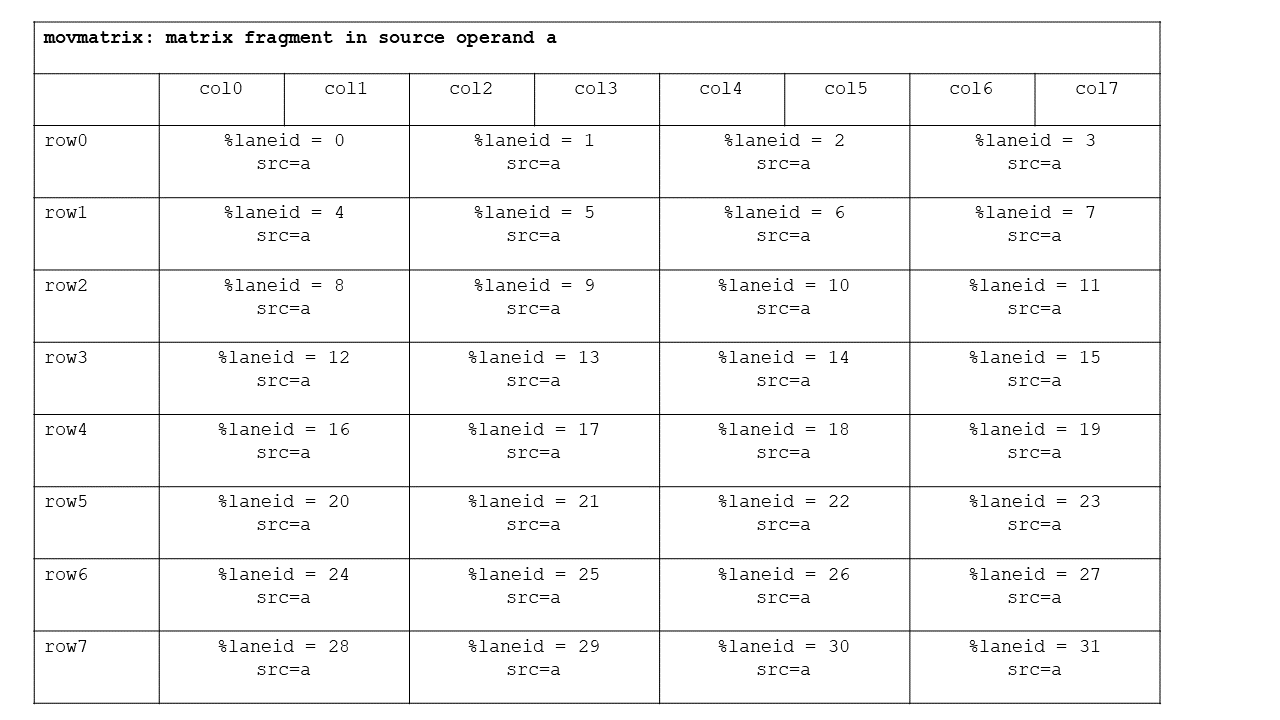
Figure 109 movmatrix source matrix fragment layout
Each thread in a warp holds a fragment of a column of the result matrix, with thread 0 holding the first fragment in register d, and so on. A group of four threads holds an entire column of the result matrix as shown in Figure 110.
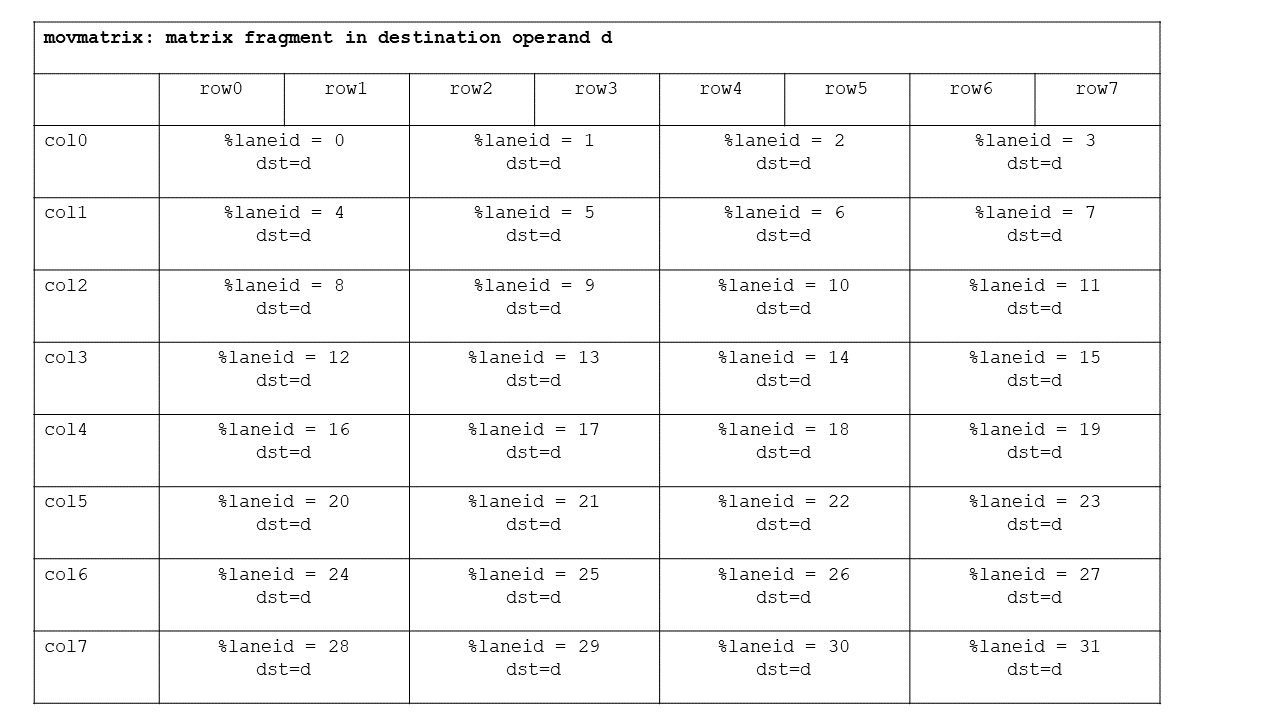
Figure 110 movmatrix result matrix fragment layout
PTX ISA Notes
Introduced in PTX ISA version 7.8.
Target ISA Notes
Requires sm_75 or higher.
Examples
.reg .b32 d, a;
movmatrix.sync.aligned.m8n8.trans.b16 d, a;