9.7.14.6.2.8. Matrix Fragments for sparse mma.m16n8k128 with .u4 / .s4 integer type
A warp executing sparse mma.m16n8k128 with .u4 / .s4 / .e2m1 integer type will compute an MMA operation of shape .m16n8k128.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements |
|---|---|---|
.u4 / .s4 |
A vector expression containing four .b32 registers, with each register containing eight non-zero .u4 / .s4 elements out of 16 consecutive elements from matrix A. Mapping of the non-zero elements is as described in Sparse matrix storage. |
|
.e2m1 |
A vector expression containing four .b32 registers, with each register containing eight non-zero .e2m1 elements out of 16 consecutive elements from matrix A. |
The layout of the fragments held by different threads is shown in Figure 140 and Figure 141.
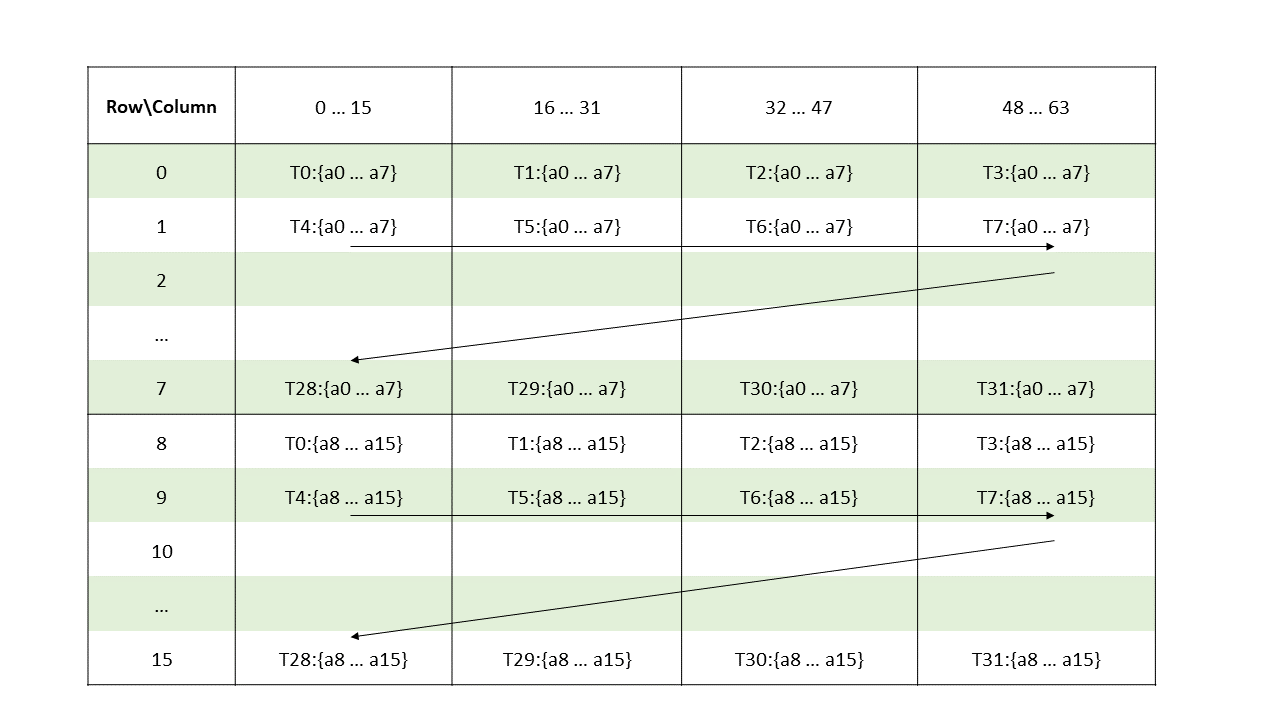
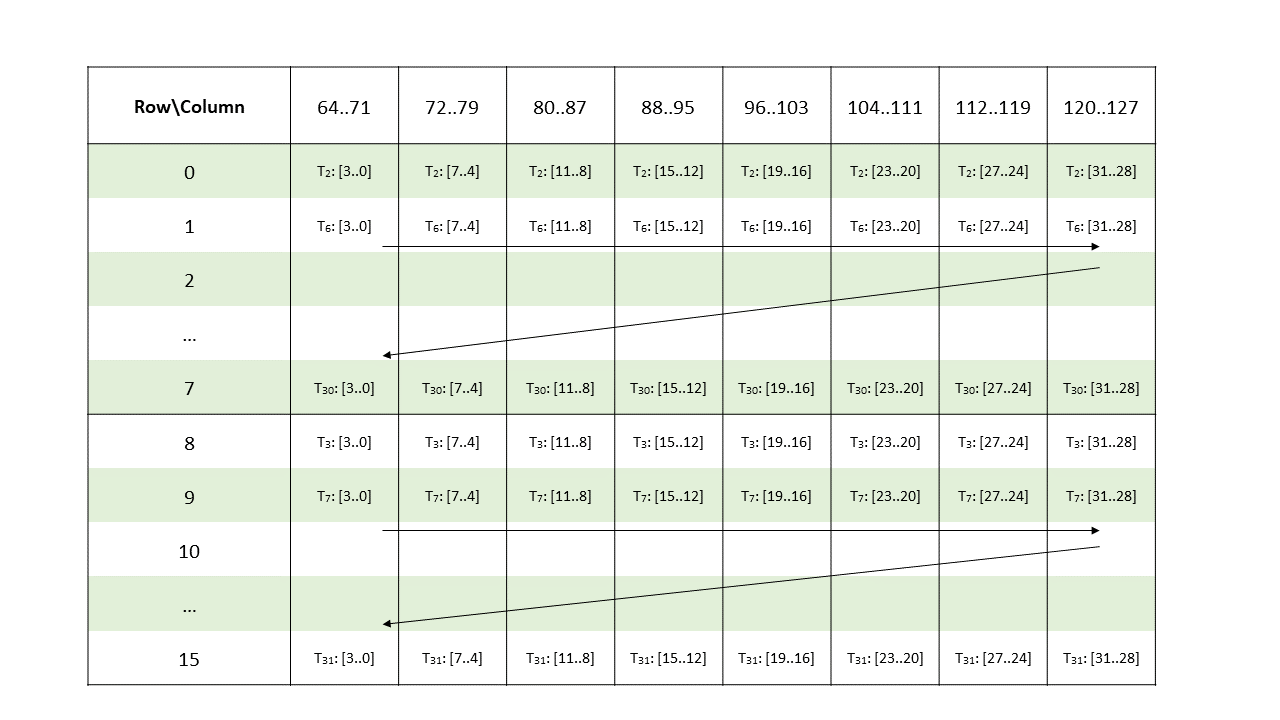
Figure 140 Sparse MMA .m16n8k128 fragment layout for columns 0–63 of matrix A with .u4/.s4/.e2m1 type.
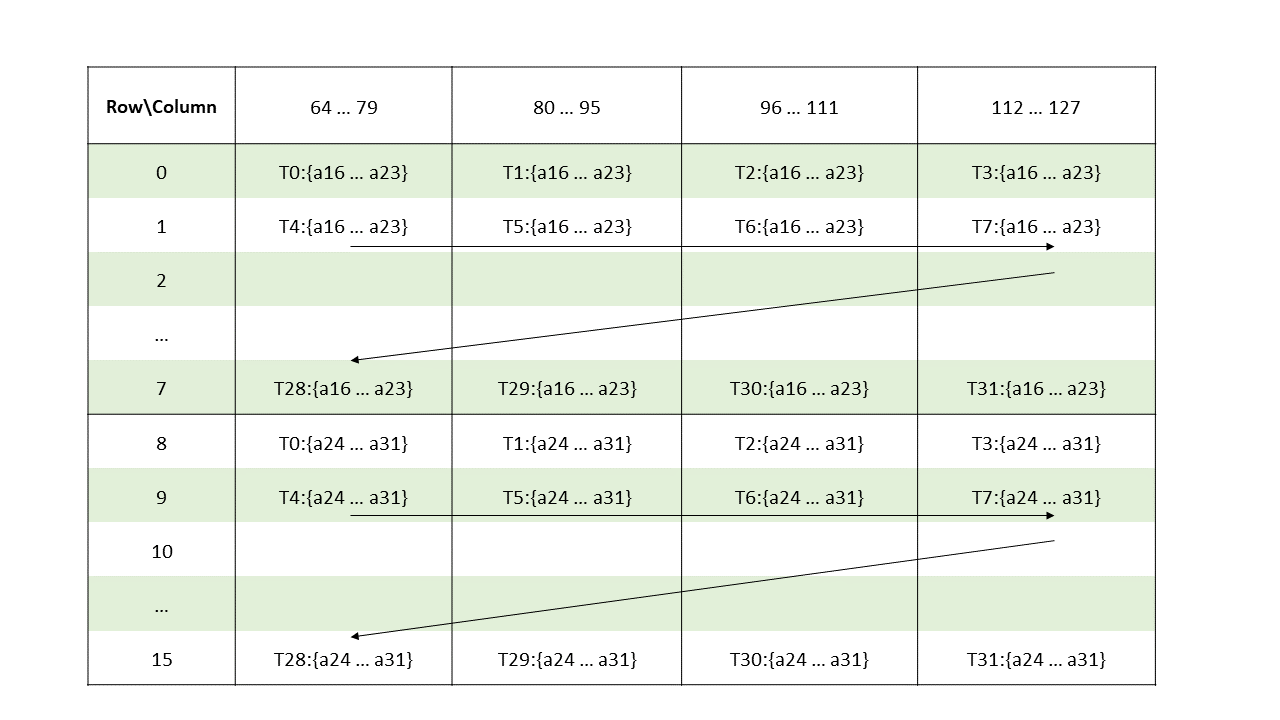
Figure 141 Sparse MMA .m16n8k128 fragment layout for columns 64–127 of matrix A with .u4/.s4/.e2m1 type.
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for ai where 0 <= i < 8 || 16 <= i < 24
groupID + 8 Otherwise
col = [firstcol ... lastcol] // As per the mapping of non-zero elements
// as described in Sparse matrix storage
Where
firstcol = threadID_in_group * 16 For ai where i < 16
(threadID_in_group * 16) + 64 For ai where i >= 16
lastcol = firstcol + 15Multiplicand B:
.atype |
Fragment | Elements (low to high) |
|---|---|---|
.u4 / .s4 |
A vector expression containing four .b32 registers, each containing eight .u4 / .s4 elements from matrix B. |
b0, b1, b2, b3, …, b31 |
.e2m1 |
A vector expression containing four .b32 registers, each containing eight .e2m1 elements from matrix B. |
The layout of the fragments held by different threads is shown in Figure 142, Figure 143, Figure 144, Figure 145.
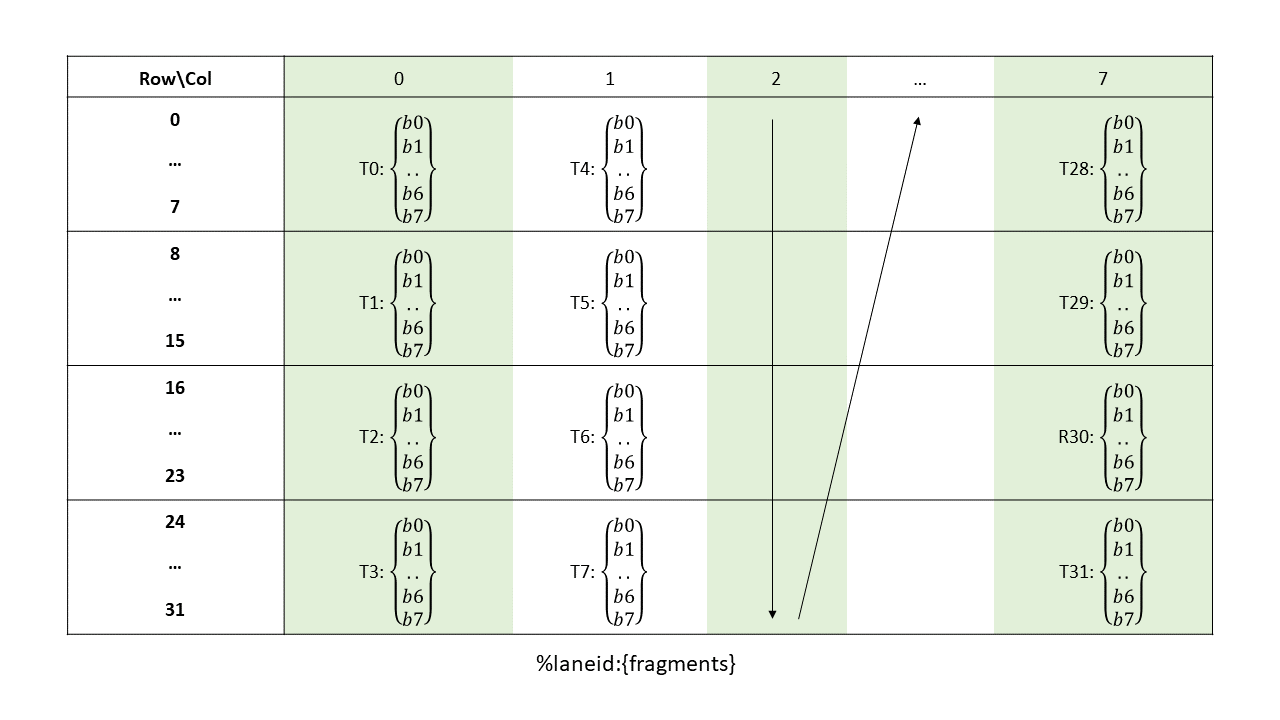
Figure 142 Sparse MMA .m16n8k128 fragment layout for rows 0–31 of matrix B with .u4/.s4/.e2m1 type.
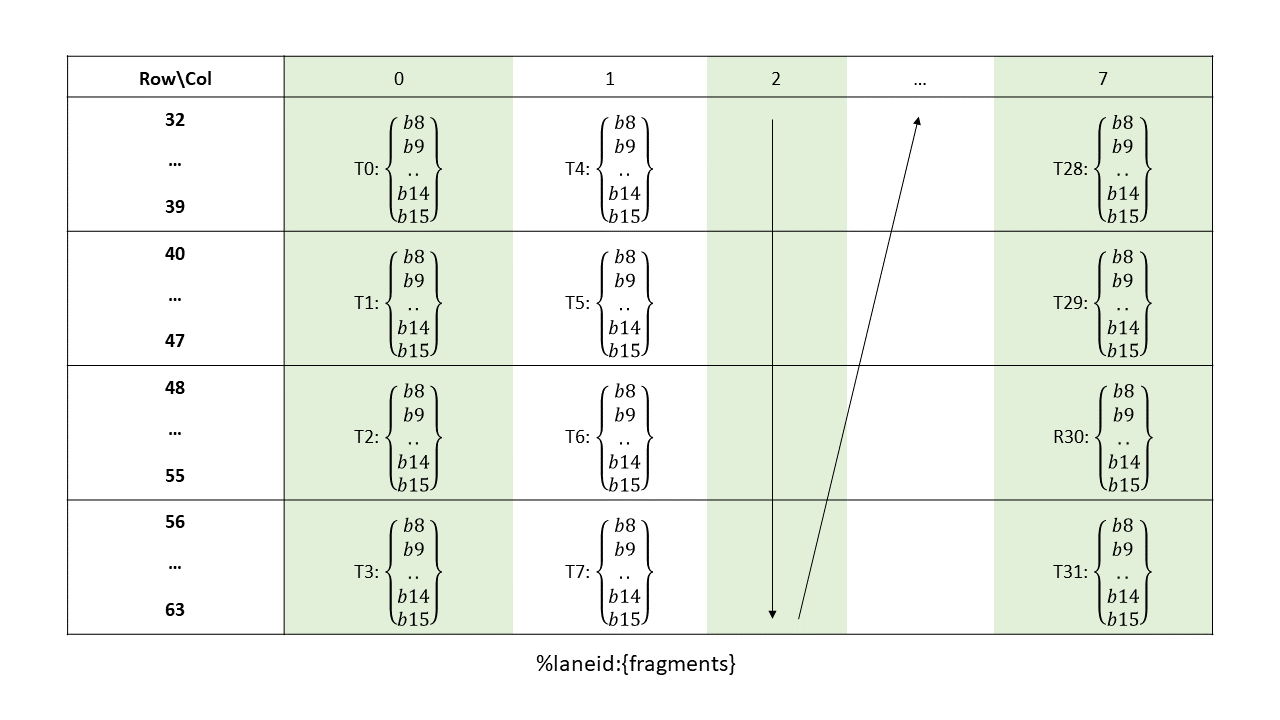
Figure 143 Sparse MMA .m16n8k128 fragment layout for rows 32–63 of matrix B with .u4/.s4/.e2m1 type.
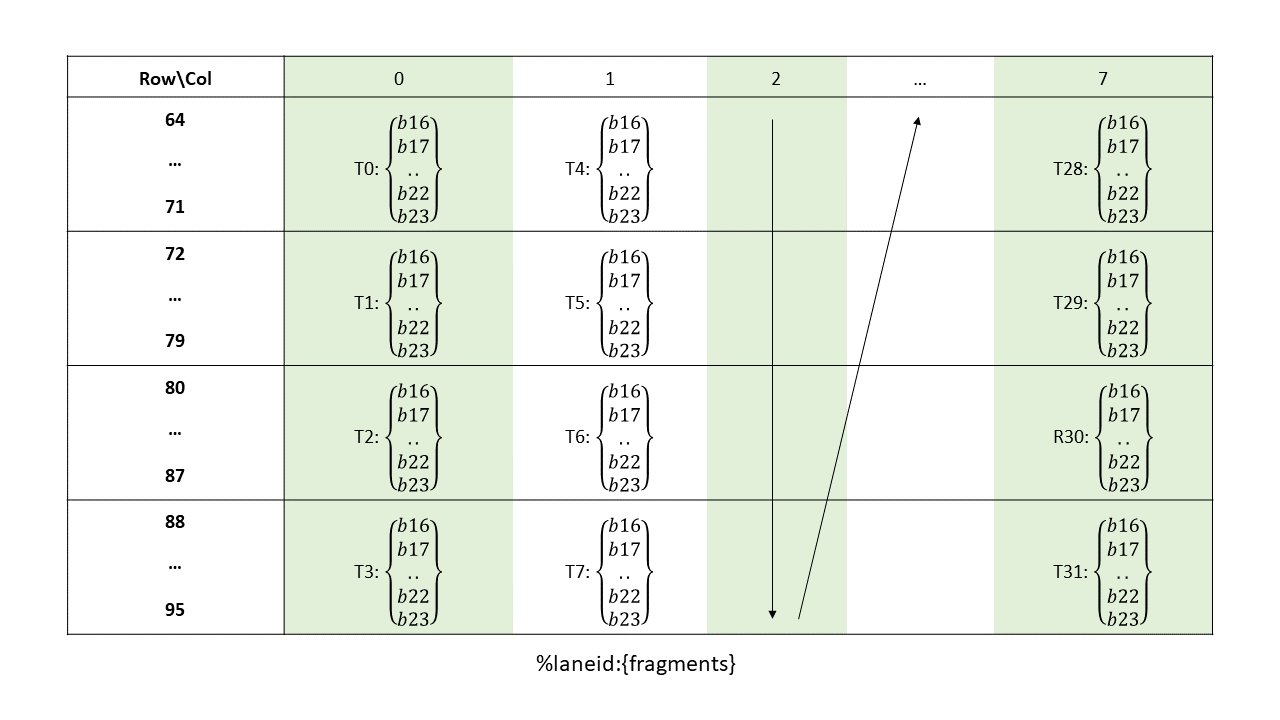
Figure 144 Sparse MMA .m16n8k128 fragment layout for rows 64–95 of matrix B with .u4/.s4/.e2m1 type.
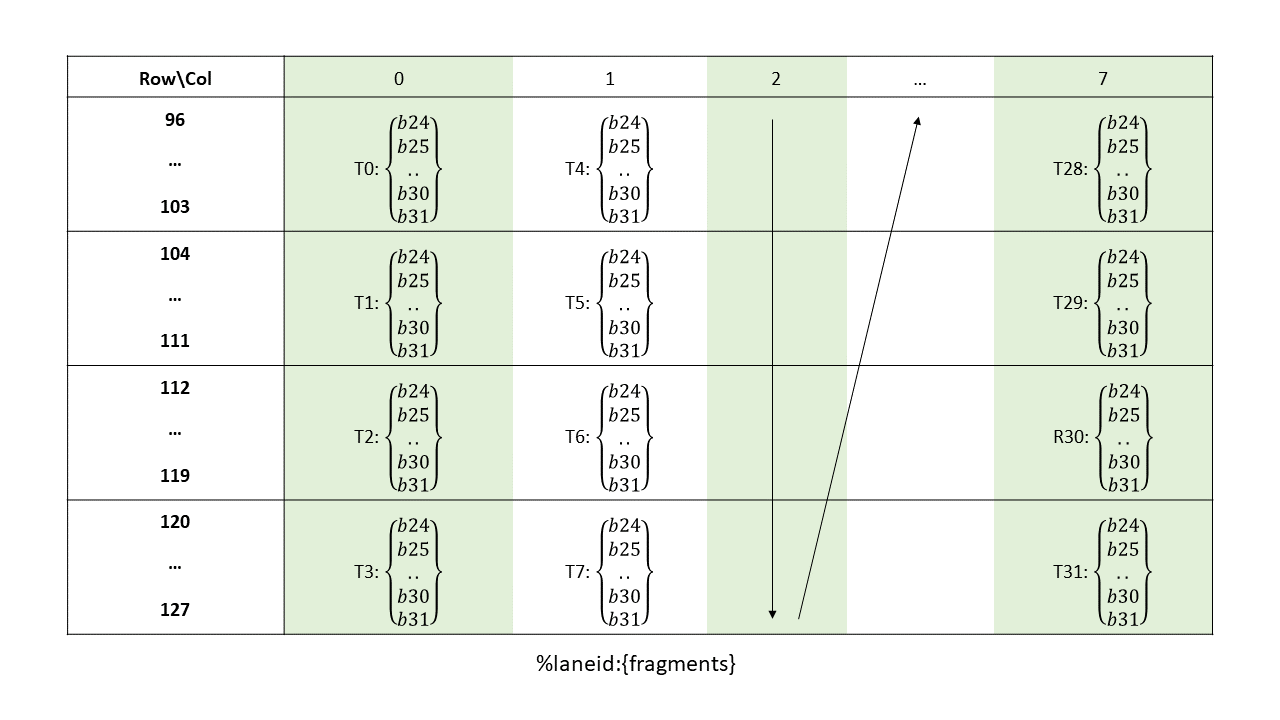
Figure 145 Sparse MMA .m16n8k128 fragment layout for rows 96–127 of matrix B with .u4/.s4/.e2m1 type.
Matrix fragments for accumulators C and D are the same as in case of Matrix Fragments for mma.m16n8k64.
Metadata: A .b32 register containing 16 2-bit vectors with each pair of 2-bit vectors storing the indices of four non-zero elements from a 8-wide chunk of matrix A as shown in Figure 146 and Figure 147.
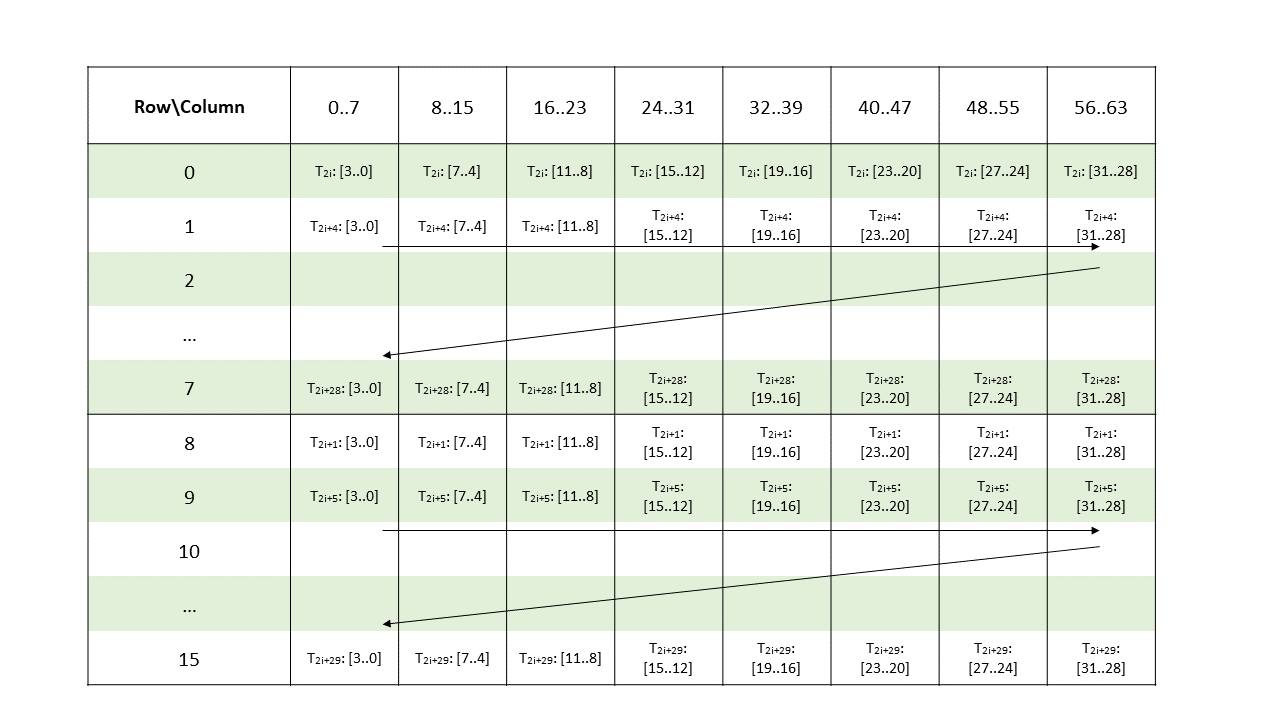
Figure 146 Sparse MMA .m16n8k128 metadata layout for columns 0–63 for .u4/.s4/.e2m1 type.