9.7.14.6.2. Matrix fragments for multiply-accumulate operation with sparse matrix A
In this section we describe how the contents of thread registers are associated with fragments of various matrices and the sparsity metadata. The following conventions are used throughout this section:
- For matrix A, only the layout of a fragment is described in terms of register vector sizes and their association with the matrix data.
- For matrix B, when the combination of matrix dimension and the supported data type is not already covered in Matrix multiply-accumulate operation using mma instruction, a pictorial representation of matrix fragments is provided.
- For matrices C and D, since the matrix dimension - data type combination is the same for all supported shapes, and is already covered in Matrix multiply-accumulate operation using mma instruction, the pictorial representations of matrix fragments are not included in this section.
- For the metadata operand, pictorial representations of the association between indices of the elements of matrix A and the contents of the metadata operand are included.
Tk: [m..n]present in cell[x][y..z]indicates that bits m through n (with m being higher) in the metadata operand of thread with%laneid=kcontains the indices of the non-zero elements from the chunk[x][y]..[x][z]of matrix A.
9.7.14.6.2.1. Matrix Fragments for sparse mma.m16n8k16 with .f16 and .bf16 types
A warp executing sparse mma.m16n8k16 with .f16 / .bf16 floating point type will compute an MMA operation of shape .m16n8k16.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements |
|---|---|---|
.f16 / .bf16 |
A vector expression containing two .b32 registers, with each register containing two non-zero .f16 / .bf16 elements out of 4 consecutive elements from matrix A. Mapping of the non-zero elements is as described in Sparse matrix storage. |
The layout of the fragments held by different threads is shown in Figure 118.
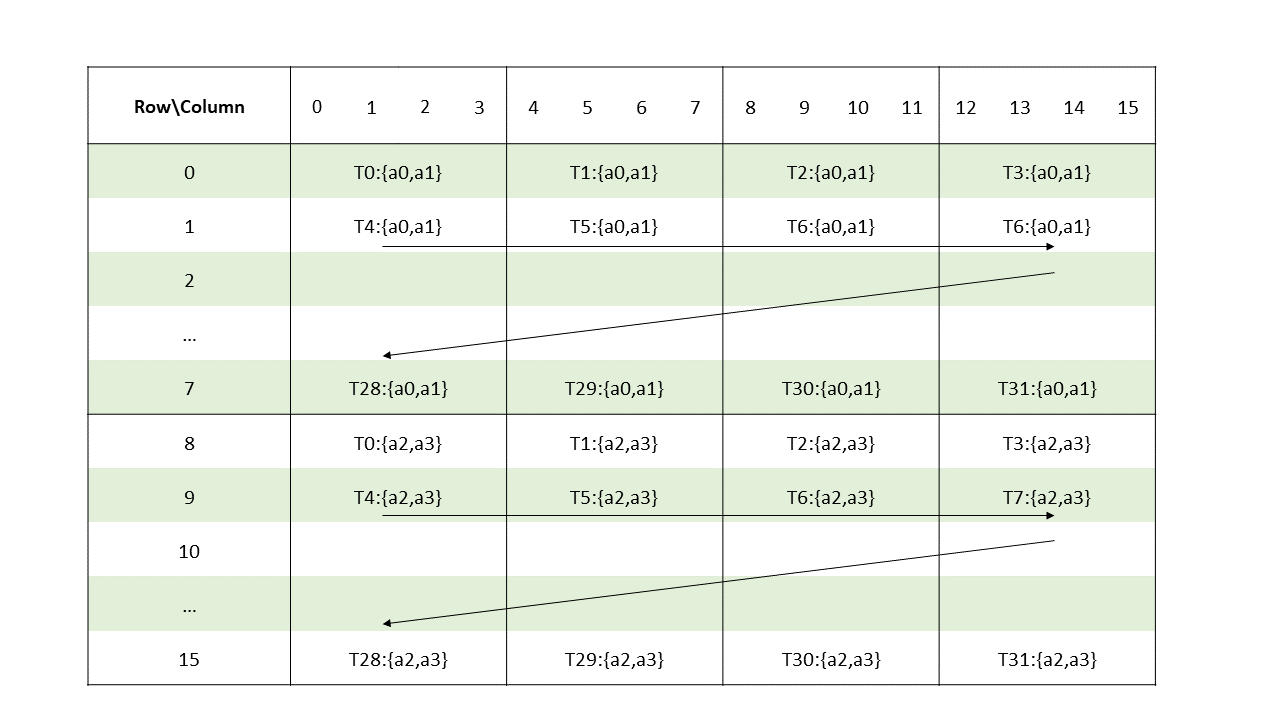
Figure 118 Sparse MMA .m16n8k16 fragment layout for matrix A with .f16/.bf16 type.
The row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for a0 and a1
groupID + 8 for a2 and a3
col = [firstcol ... lastcol] // As per the mapping of non-zero elements
// as described in Sparse matrix storage
Where
firstcol = threadID_in_group * 4
lastcol = firstcol + 3Matrix fragments for multiplicand B and accumulators C and D are the same as in case of Matrix Fragments for mma.m16n8k16 with floating point type for .f16/.b16 formats.
Metadata: A .b32 register containing 16 2-bit vectors each storing the index of a non-zero element of a 4-wide chunk of matrix A as shown in Figure 119.
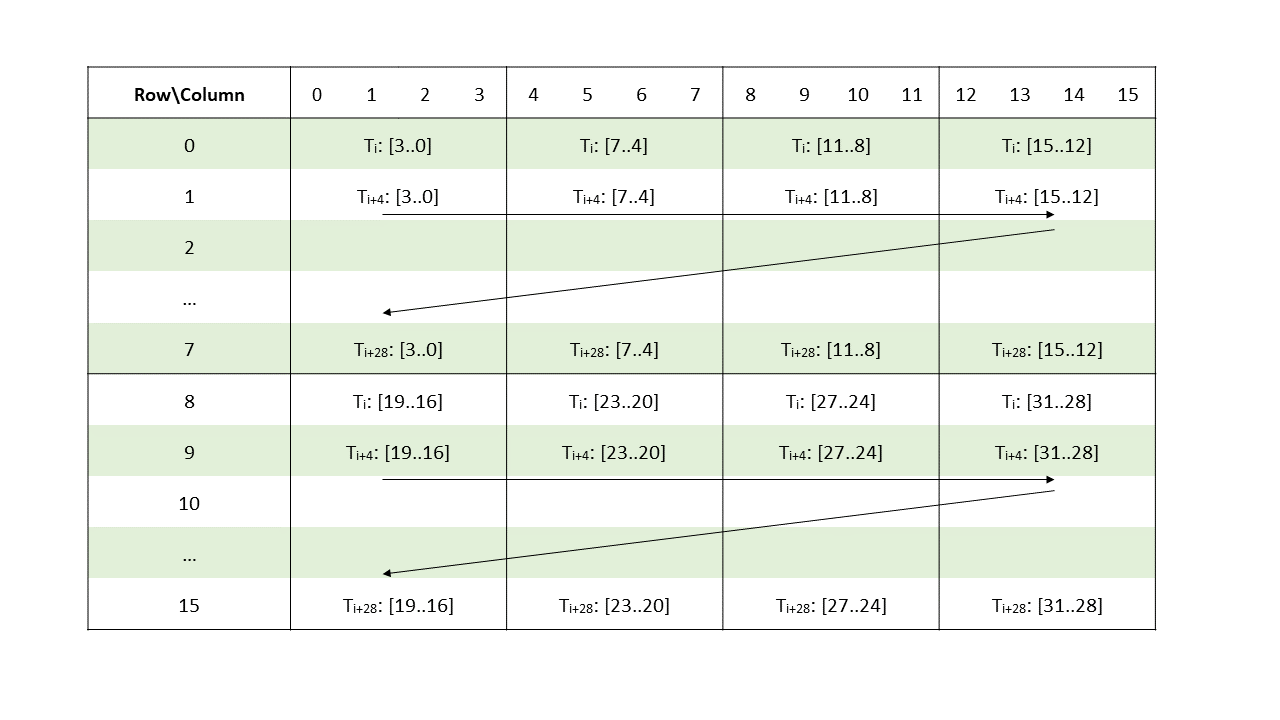
Figure 119 Sparse MMA .m16n8k16 metadata layout for .f16/.bf16 type.
9.7.14.6.2.2. Matrix Fragments for sparse mma.m16n8k32 with .f16 and .bf16 types
A warp executing sparse mma.m16n8k32 with .f16 / .bf16 floating point type will compute an MMA operation of shape .m16n8k32.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements |
|---|---|---|
.f16 / .bf16 |
A vector expression containing four .b32 registers, with each register containing two non-zero .f16 / .bf16 elements out of 4 consecutive elements from matrix A. Mapping of the non-zero elements is as described in Sparse matrix storage. |
The layout of the fragments held by different threads is shown in Figure 120.
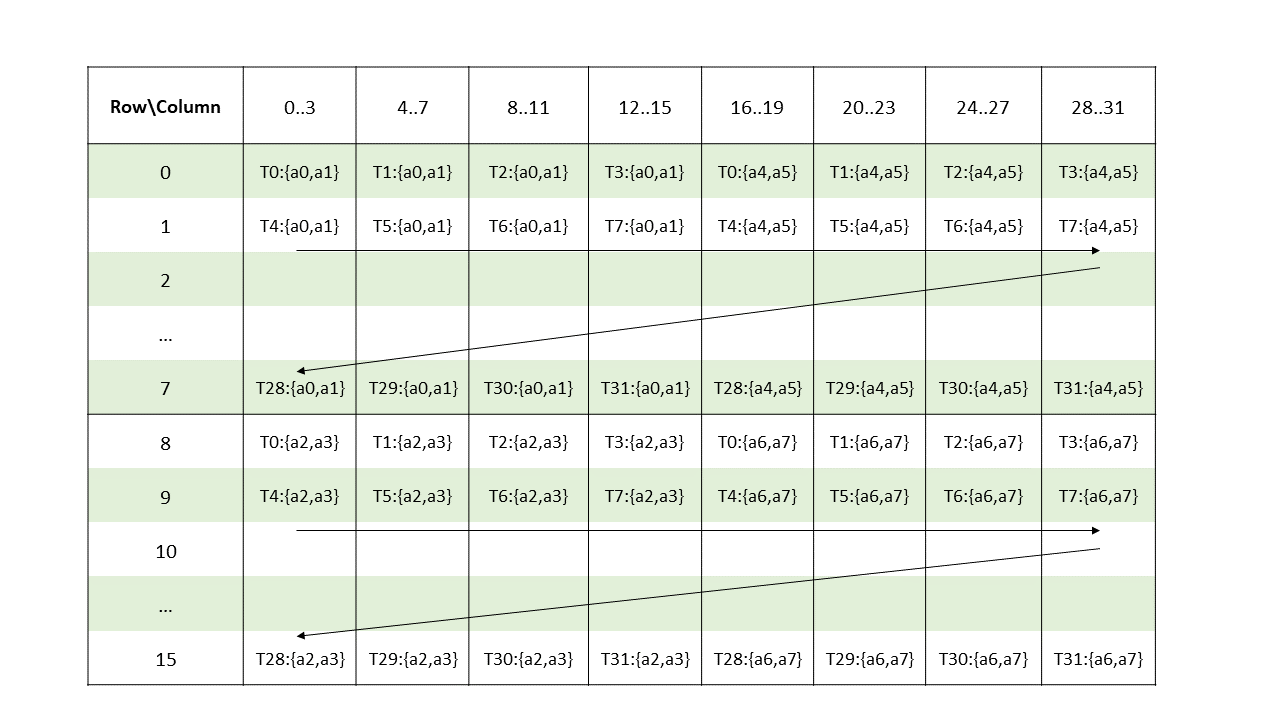
Figure 120 Sparse MMA .m16n8k32 fragment layout for matrix A with .f16/.bf16 type.
The row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for ai where 0 <= i < 2 || 4 <= i < 6
groupID + 8 Otherwise
col = [firstcol ... lastcol] // As per the mapping of non-zero elements
// as described in Sparse matrix storage
Where
firstcol = threadID_in_group * 4 For ai where i < 4
(threadID_in_group * 4) + 16 for ai where i >= 4
lastcol = firstcol + 3Multiplicand B:
.atype |
Fragment | Elements (low to high) |
|---|---|---|
.f16 / .bf16 |
A vector expression containing four .b32 registers, each containing two .f16 / .bf16 elements from matrix B. |
b0, b1, b2, b3 |
The layout of the fragments held by different threads is shown in Figure 121.
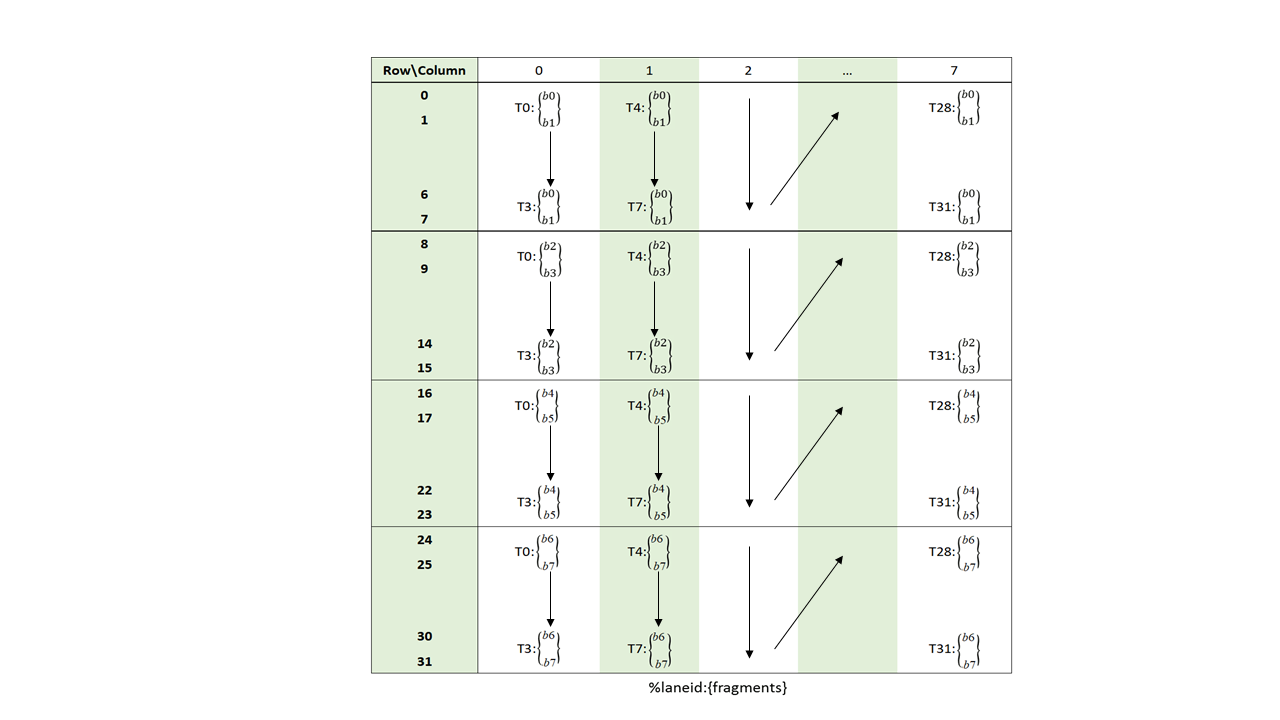
Figure 121 Sparse MMA .m16n8k32 fragment layout for matrix B with .f16/.bf16 type.
Matrix fragments for accumulators C and D are the same as in case of Matrix Fragments for mma.m16n8k16 with floating point type for .f16/.b16 formats.
Metadata: A .b32 register containing 16 2-bit vectors with each pair of 2-bit vectors storing the indices of two non-zero element from a 4-wide chunk of matrix A as shown in Figure 122.
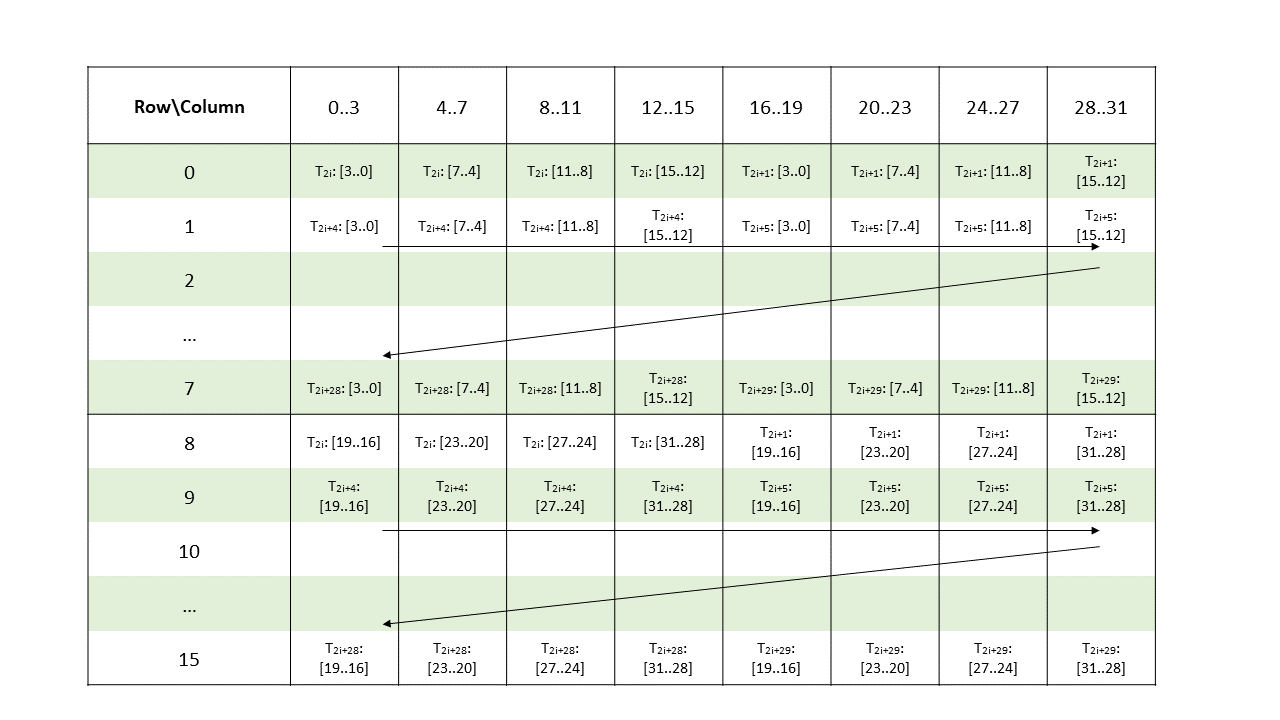
Figure 122 Sparse MMA .m16n8k32 metadata layout for .f16/.bf16 type.
9.7.14.6.2.3. Matrix Fragments for sparse mma.m16n8k16 with .tf32 floating point type
A warp executing sparse mma.m16n8k16 with .tf32 floating point type will compute an MMA operation of shape .m16n8k16.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements |
|---|---|---|
.tf32 |
A vector expression containing four .b32 registers, with each register containing one non-zero .tf32 element out of 2 consecutive elements from matrix A. Mapping of the non-zero elements is as described in Sparse matrix storage. |
The layout of the fragments held by different threads is shown in Figure 123.
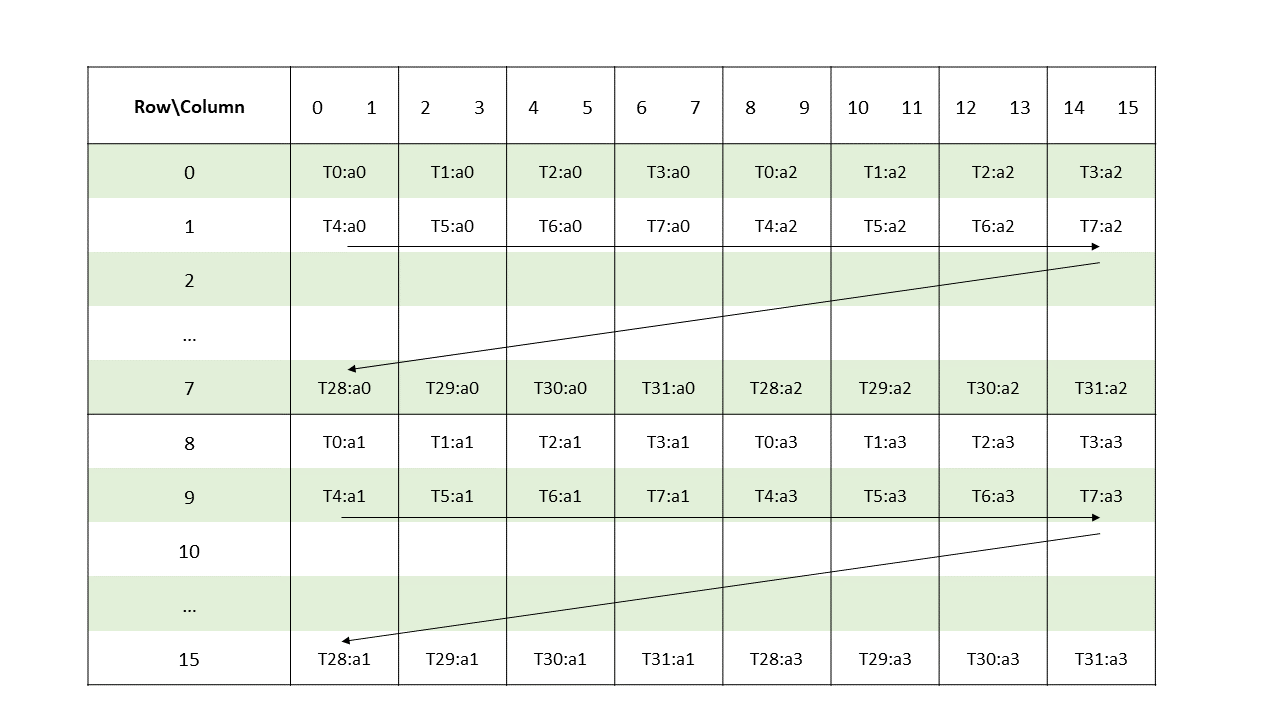
Figure 123 Sparse MMA .m16n8k16 fragment layout for matrix A with .tf32 type.
The row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for a0 and a2
groupID + 8 for a1 and a3
col = [firstcol ... lastcol] // As per the mapping of non-zero elements
// as described in Sparse matrix storage
Where
firstcol = threadID_in_group * 2 for a0 and a1
(threadID_in_group * 2) + 8 for a2 and a3
lastcol = firstcol + 1Multiplicand B:
.atype |
Fragment | Elements (low to high) |
|---|---|---|
.tf32 |
A vector expression containing four .b32 registers, each containing four .tf32 elements from matrix B. |
b0, b1, b2, b3 |
The layout of the fragments held by different threads is shown in Figure 124.
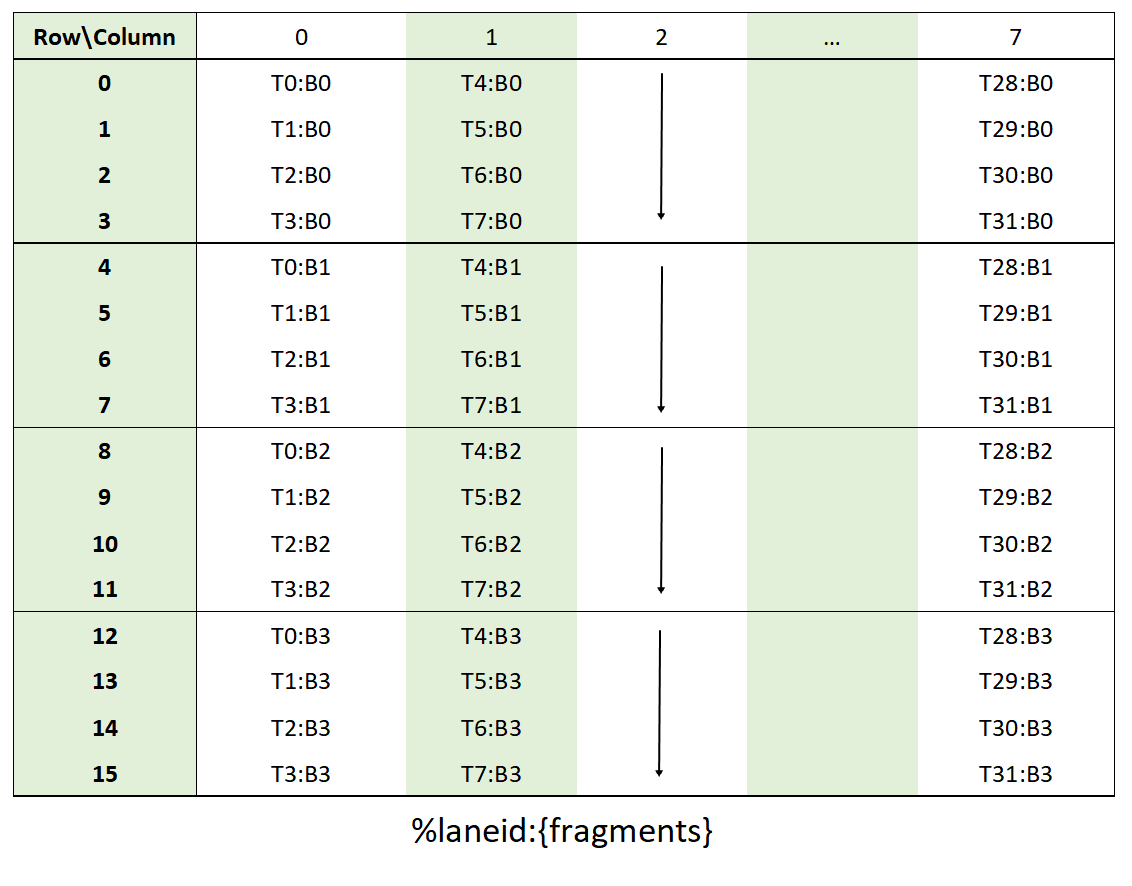
Figure 124 Sparse MMA .m16n8k16 fragment layout for matrix B with .tf32 type.
Matrix fragments for accumulators C and D are the same as in case of Matrix Fragments for mma.m16n8k16 with floating point type.
Metadata: A .b32 register containing 8 4-bit vectors each storing the index of a non-zero element of a 2-wide chunk of matrix A as shown in Figure 125.
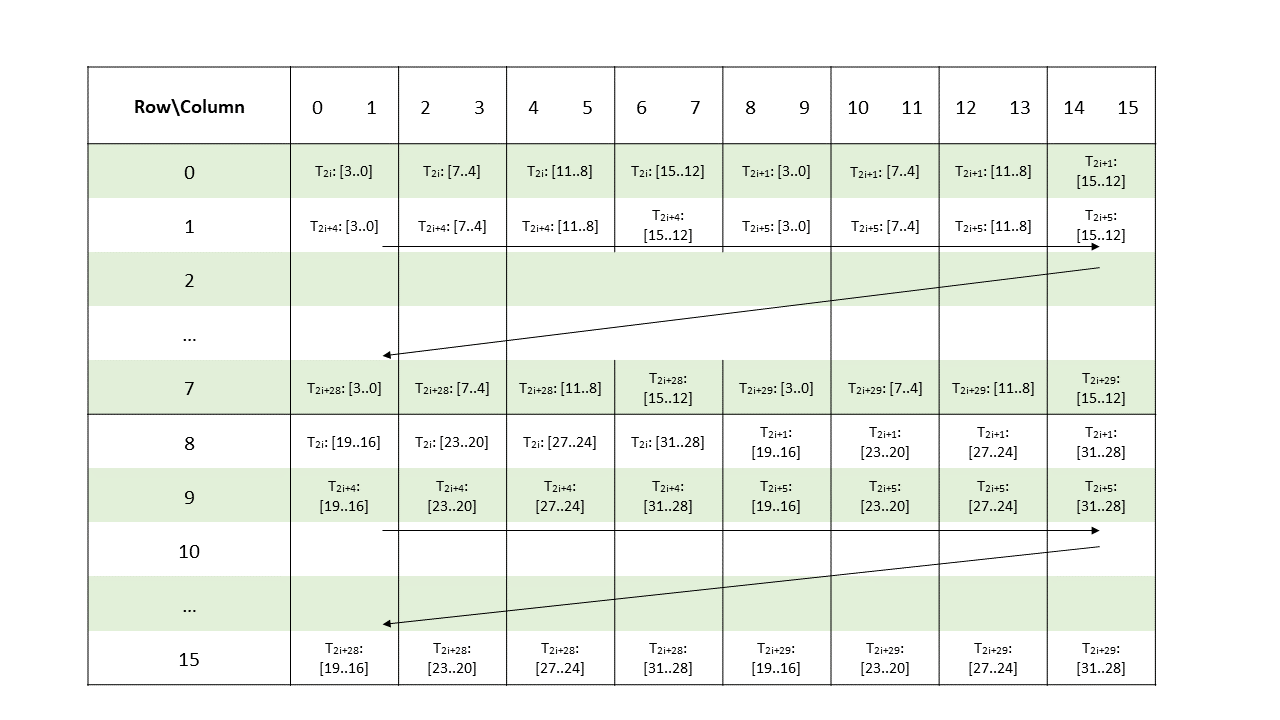
Figure 125 Sparse MMA .m16n8k16 metadata layout for .tf32 type.
9.7.14.6.2.4. Matrix Fragments for sparse mma.m16n8k8 with .tf32 floating point type
A warp executing sparse mma.m16n8k8 with .tf32 floating point type will compute an MMA operation of shape .m16n8k8.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements |
|---|---|---|
.tf32 |
A vector expression containing two .b32 registers, each containing one non-zero .tf32 element out of 2 consecutive elements from matrix A. Mapping of the non-zero elements is as described in Sparse matrix storage. |
The layout of the fragments held by different threads is shown in Figure 126.
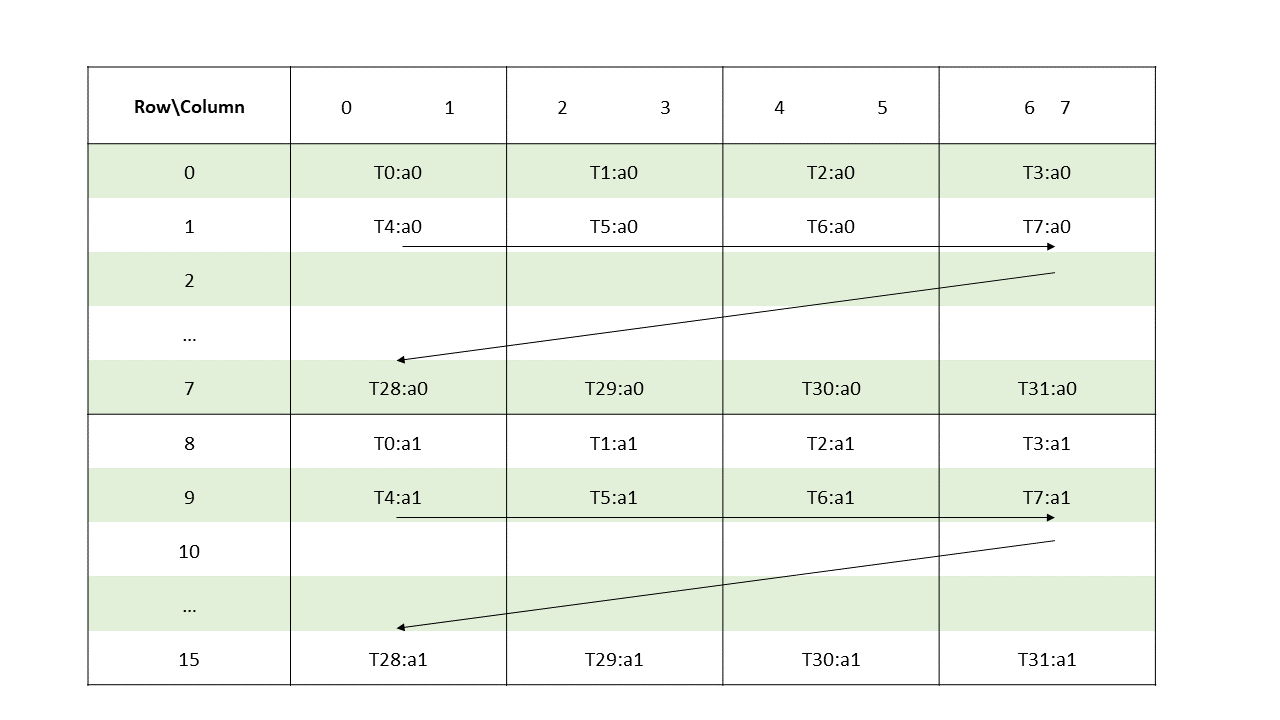
Figure 126 Sparse MMA .m16n8k8 fragment layout for matrix A with .tf32 type.
The row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for a0
groupID + 8 for a1
col = [firstcol ... lastcol] // As per the mapping of non-zero elements
// as described in Sparse matrix storage
Where
firstcol = threadID_in_group * 2
lastcol = firstcol + 1Matrix fragments for multiplicand B and accumulators C and D are the same as in case of Matrix Fragments for mma.m16n8k8 for .tf32 format.
Metadata: A .b32 register containing 8 4-bit vectors each storing the index of a non-zero element of a 2-wide chunk of matrix A as shown in Figure 127.
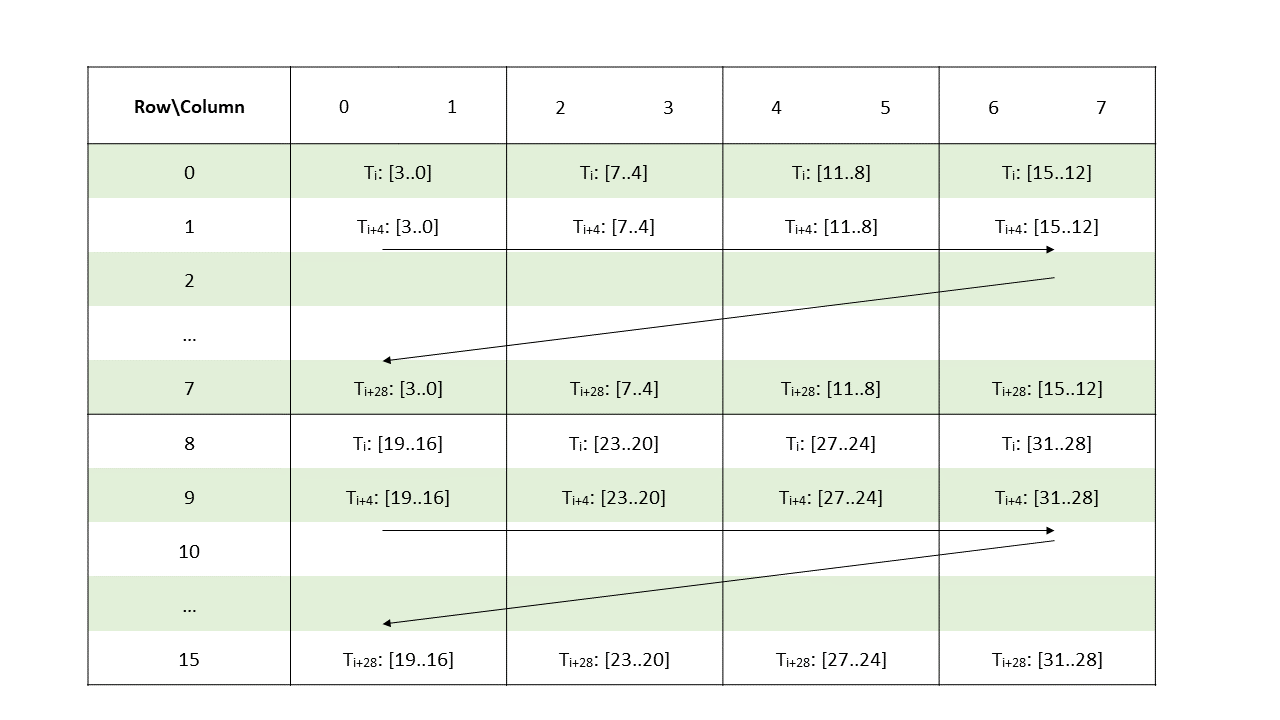
Figure 127 Sparse MMA .m16n8k8 metadata layout for .tf32 type.
9.7.14.6.2.5. Matrix Fragments for sparse mma.m16n8k32 with .u8 / .s8 integer type
A warp executing sparse mma.m16n8k32 with .u8 / .s8 integer type will compute an MMA operation of shape .m16n8k32.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements |
|---|---|---|
.u8 / .s8 |
A vector expression containing two .b32 registers, with each register containing four non-zero .u8 / .s8 elements out of 8 consecutive elements from matrix A. Mapping of the non-zero elements is as described in Sparse matrix storage. |
The layout of the fragments held by different threads is shown in Figure 128.
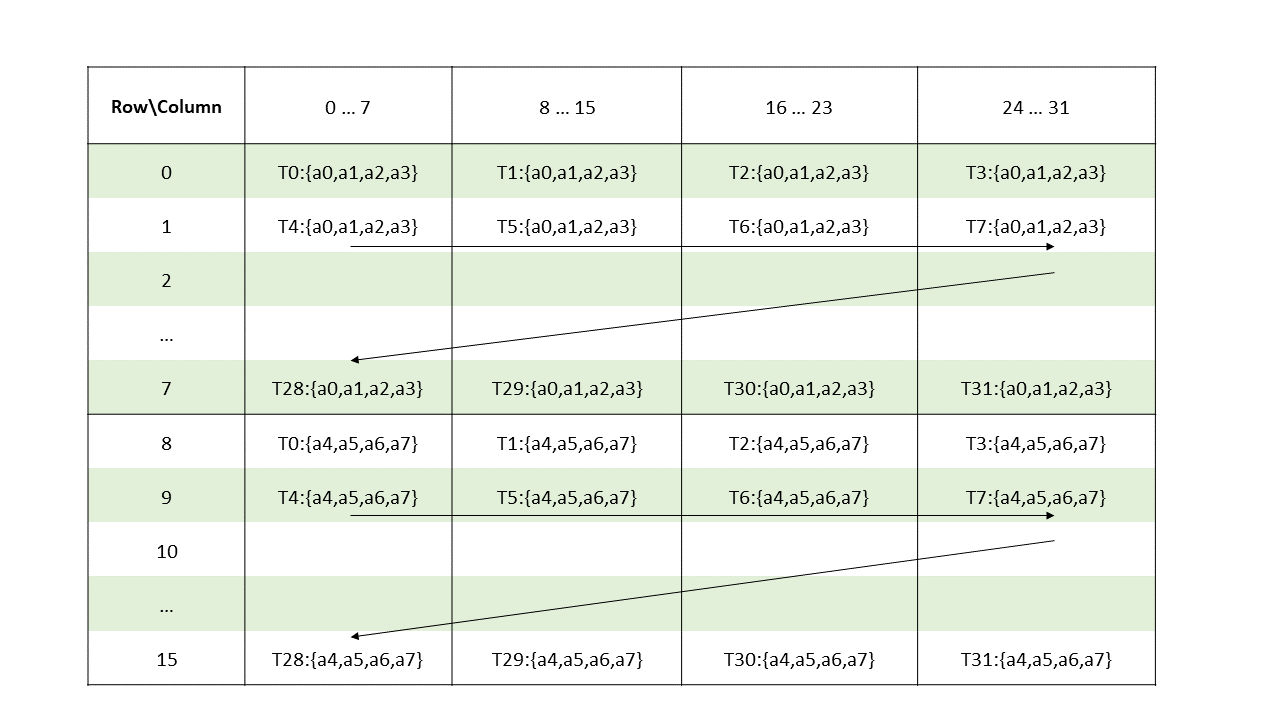
Figure 128 Sparse MMA .m16n8k32 fragment layout for matrix A with .u8/.s8 type.
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for ai where 0 <= i < 4
groupID + 8 Otherwise
col = [firstcol ... lastcol] // As per the mapping of non-zero elements
// as described in Sparse matrix storage
Where
firstcol = threadID_in_group * 8
lastcol = firstcol + 7Matrix fragments for multiplicand B and accumulators C and D are the same as in case of Matrix Fragments for mma.m16n8k32.
Metadata: A .b32 register containing 16 2-bit vectors with each pair of 2-bit vectors storing the indices of two non-zero elements from a 4-wide chunk of matrix A as shown in Figure 129.
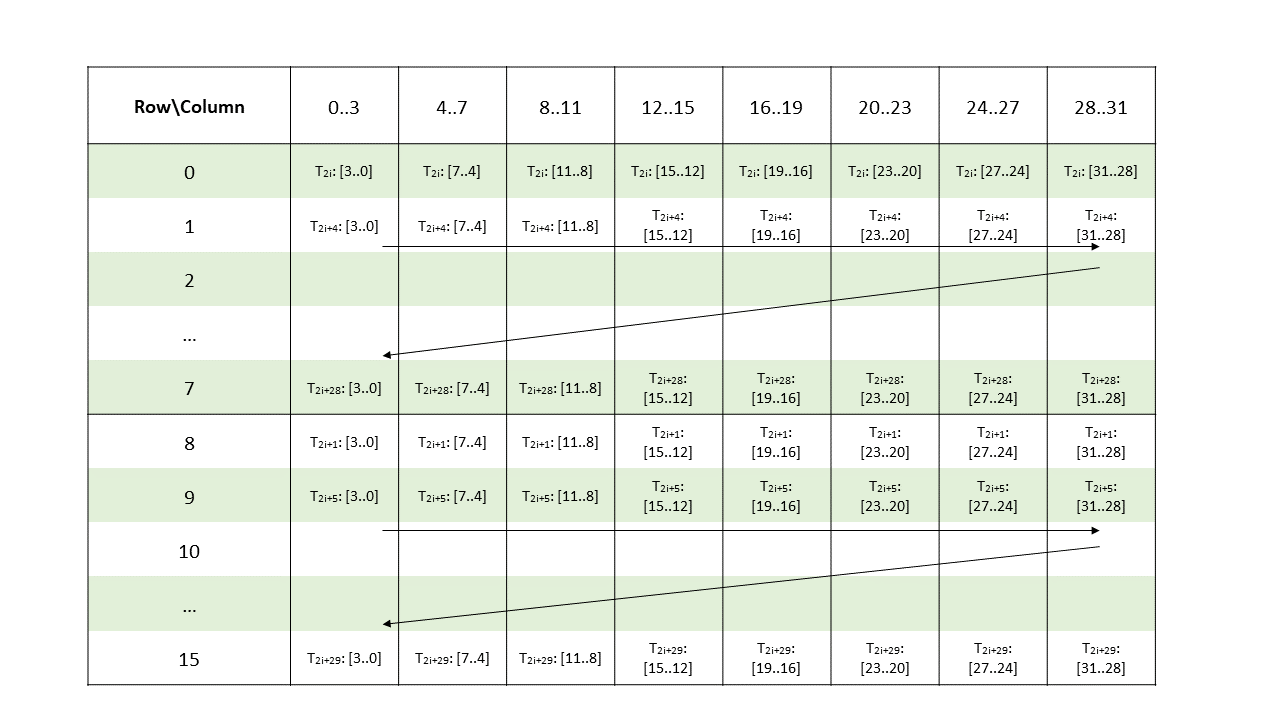
Figure 129 Sparse MMA .m16n8k32 metadata layout for .u8/.s8 type.
9.7.14.6.2.6. Matrix Fragments for sparse mma.m16n8k64 with .u8 / .s8 / .e4m3 / .e5m2 type
A warp executing sparse mma.m16n8k64 with .u8 / .s8/ .e4m3/ .e5m2 / .e3m2 / .e2m3 / .e2m1 type will compute an MMA operation of shape .m16n8k64.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements |
|---|---|---|
.u8 / .s8 |
A vector expression containing four .b32 registers, with each register containing four non-zero .u8 / .s8 elements out of 8 consecutive elements from matrix A. Mapping of the non-zero elements is as described in Sparse matrix storage. |
|
.e4m3 / .e5m2 / .e3m2 / .e2m3 / .e2m1 |
A vector expression containing four .b32 registers, with each register containing four non-zero .e4m3 / .e5m2 / .e3m2 / .e2m3 / .e2m1 elements out of 8 consecutive elements from matrix A. |
The layout of the fragments held by different threads is shown in Figure 130 and Figure 131.
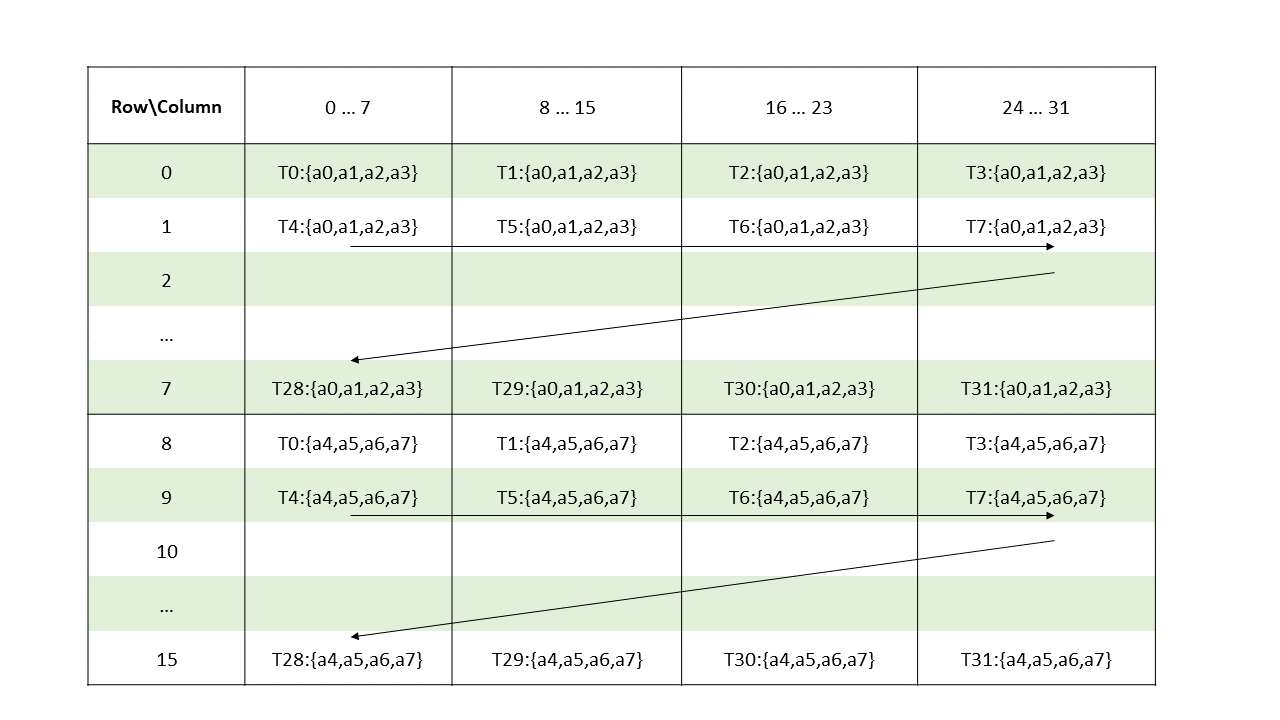
Figure 130 Sparse MMA .m16n8k64 fragment layout for columns 0–31 of matrix A with .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 type.
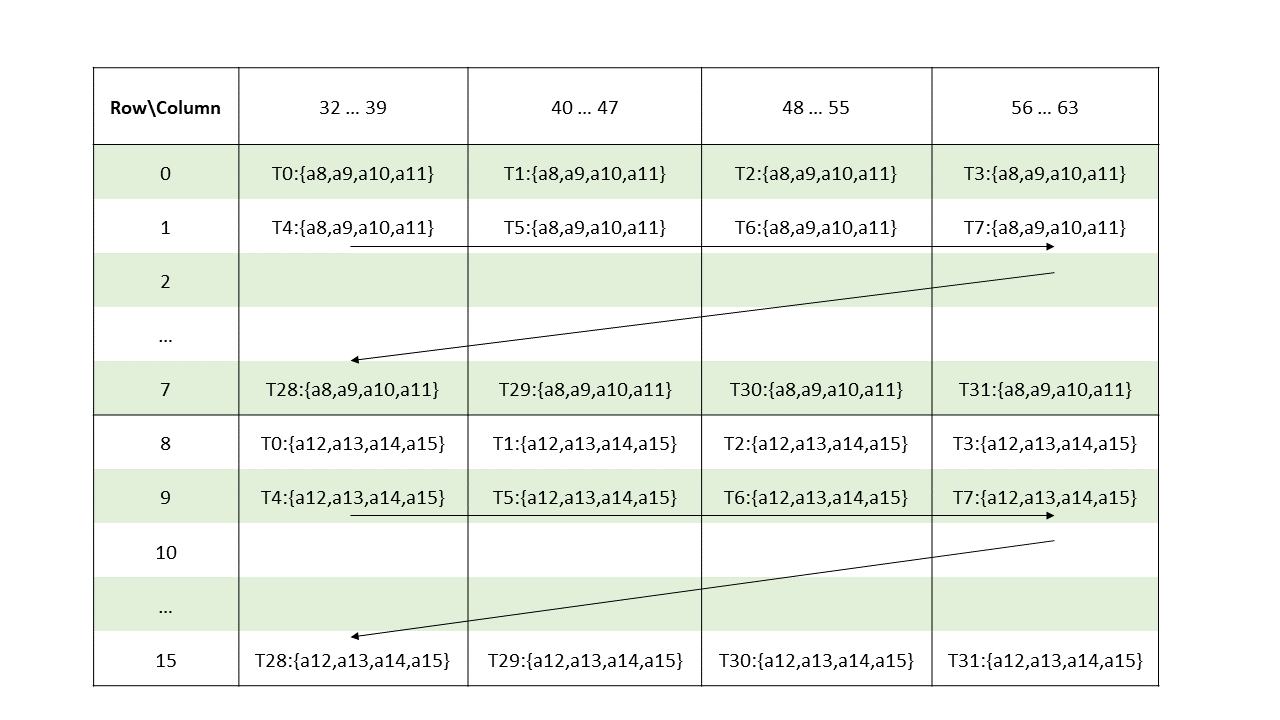
Figure 131 Sparse MMA .m16n8k64 fragment layout for columns 32–63 of matrix A with .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 type.
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for ai where 0 <= i < 4 || 8 <= i < 12
groupID + 8 Otherwise
col = [firstcol ... lastcol] // As per the mapping of non-zero elements
// as described in Sparse matrix storage
Where
firstcol = threadID_in_group * 8 For ai where i < 8
(threadID_in_group * 8) + 32 For ai where i >= 8
lastcol = firstcol + 7Multiplicand B:
.btype |
Fragment | Elements (low to high) |
|---|---|---|
.u8 / .s8 |
A vector expression containing four .b32 registers, each containing four .u8 / .s8 elements from matrix B. |
b0, b1, b2, b3, …, b15 |
.e4m3 / .e5m2 / .e3m2 / .e2m3 / .e2m1 |
A vector expression containing four .b32 registers, each containing four .e4m3 / .e5m2 / .e3m2 / .e2m3 / .e2m1 elements from matrix B. |
The layout of the fragments held by different threads is shown in Figure 132, Figure 133, Figure 134 and Figure 135.
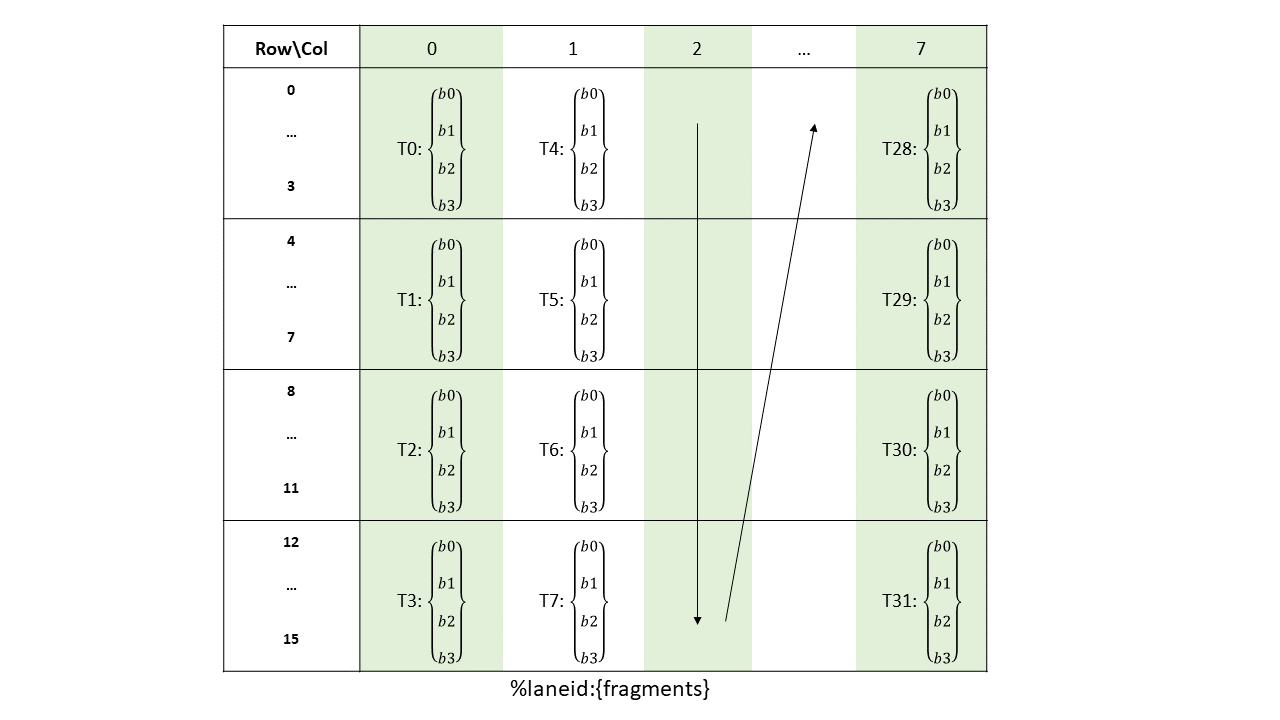
Figure 132 Sparse MMA .m16n8k64 fragment layout for rows 0–15 of matrix B with .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 type.
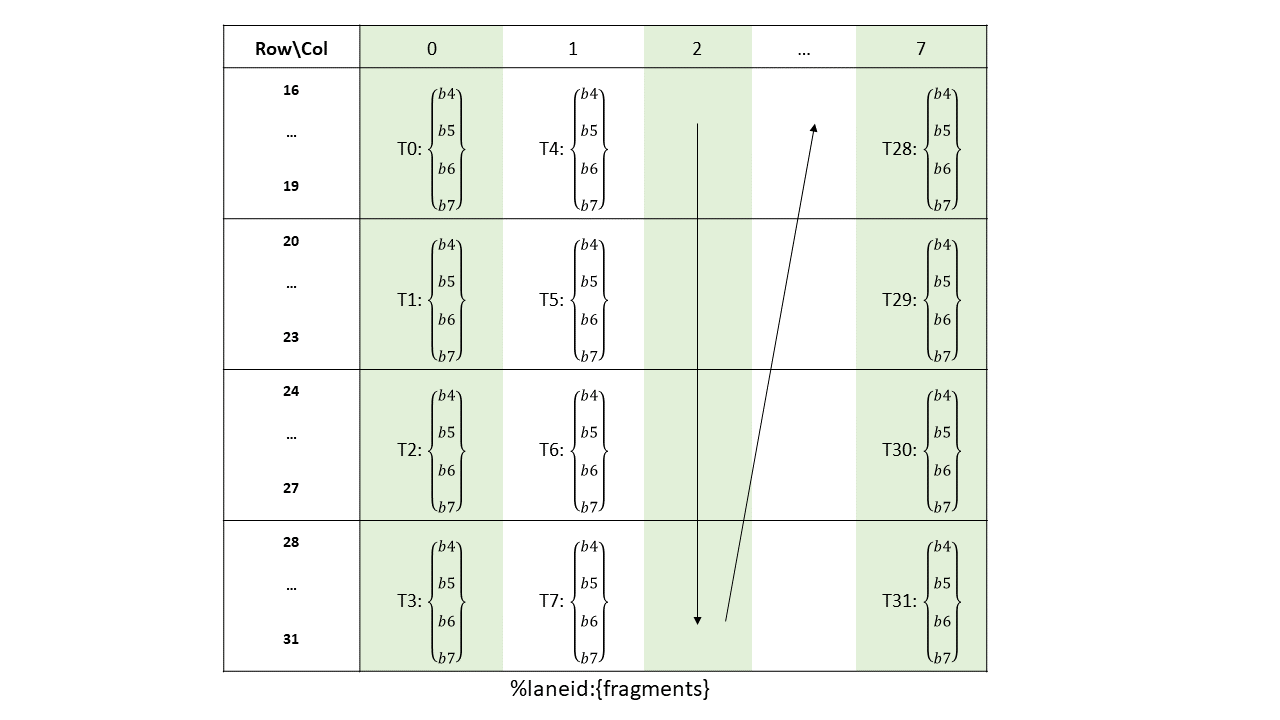
Figure 133 Sparse MMA .m16n8k64 fragment layout for rows 16–31 of matrix B with .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 type.
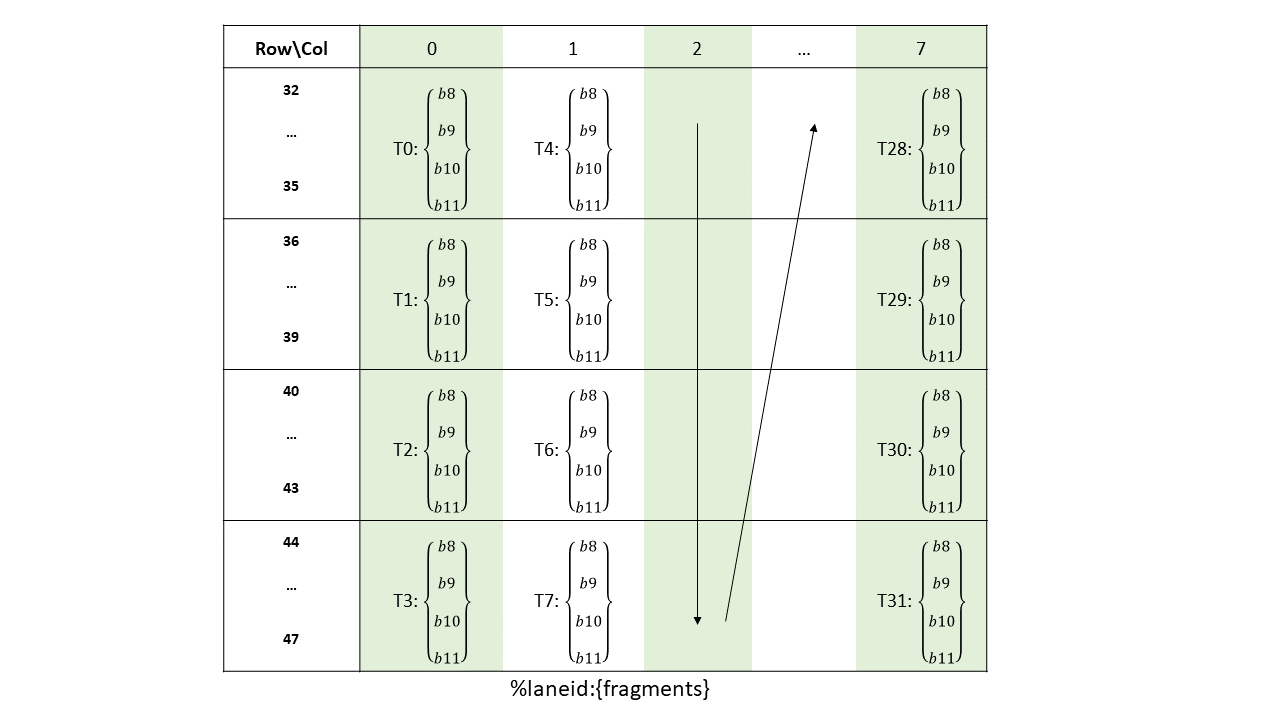
Figure 134 Sparse MMA .m16n8k64 fragment layout for rows 32–47 of matrix B with .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 type.
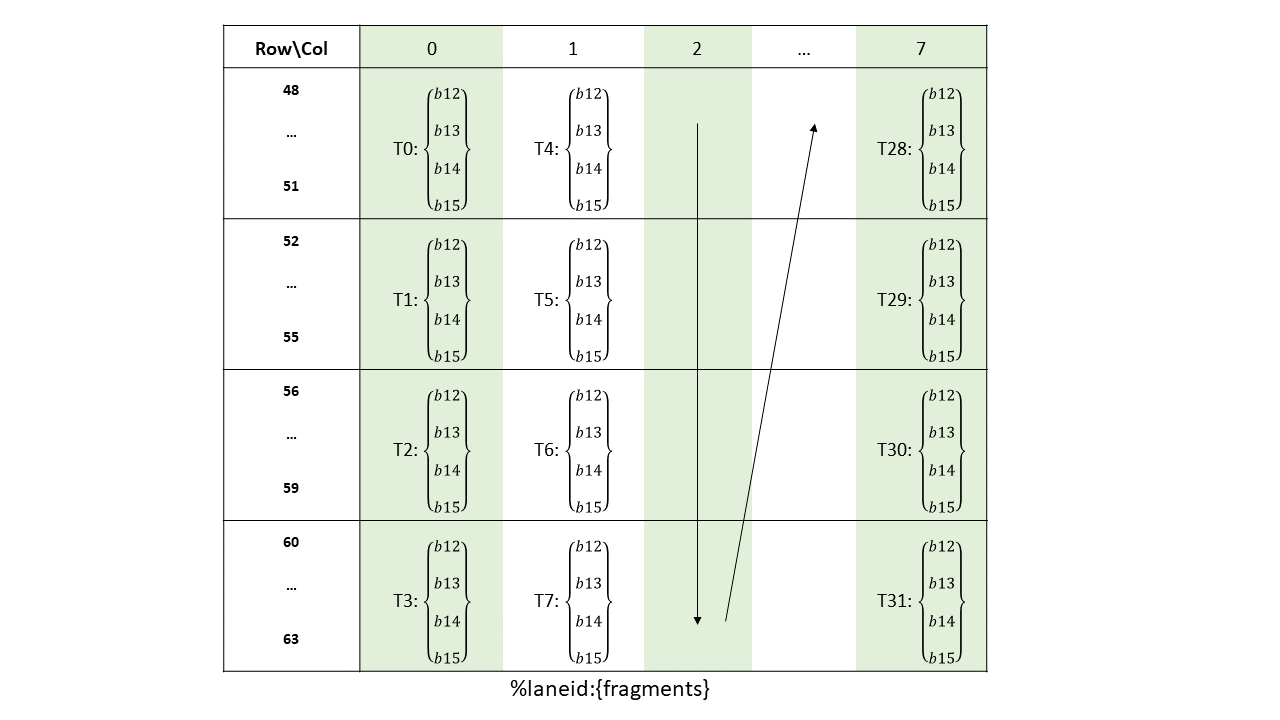
Figure 135 Sparse MMA .m16n8k64 fragment layout for rows 48–63 of matrix B with .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 type.
Matrix fragments for accumulators C and D are the same as in case of Matrix Fragments for mma.m16n8k16 with integer type.
Metadata: A .b32 register containing 16 2-bit vectors with each pair of 2-bit vectors storing the indices of two non-zero elements from a 4-wide chunk of matrix A as shown in Figure 136 and Figure 137.
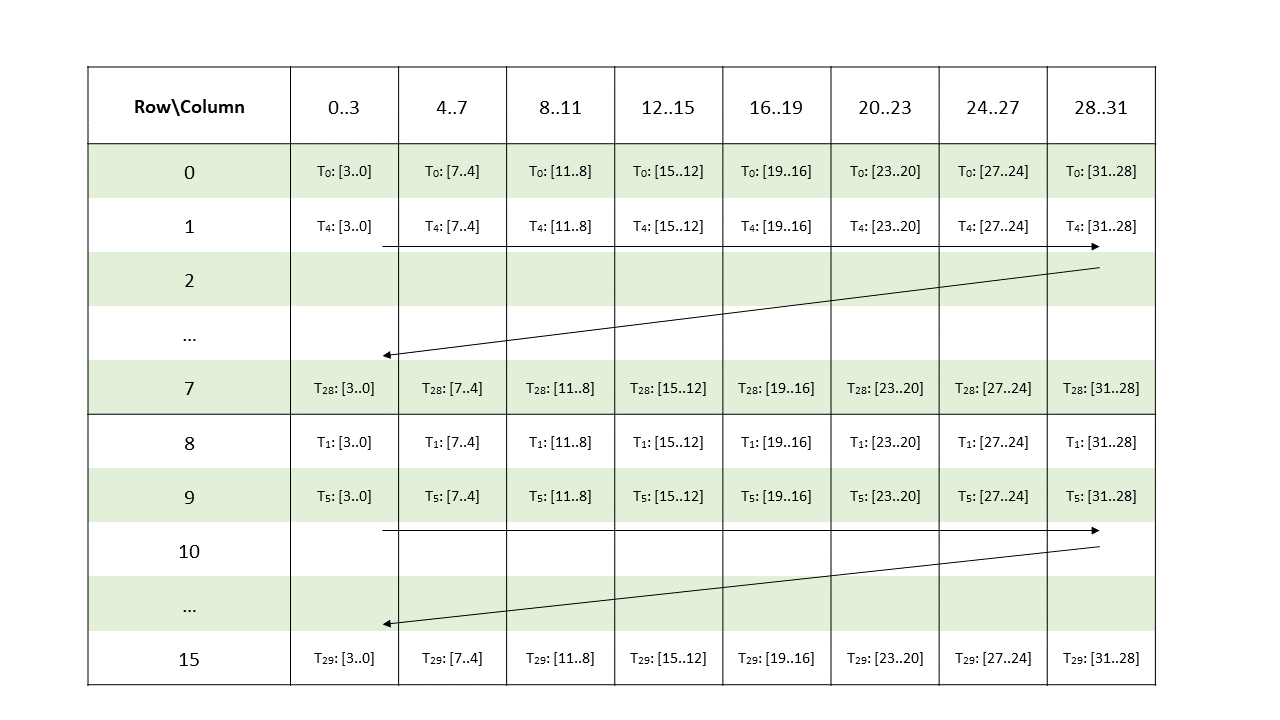
Figure 136 Sparse MMA .m16n8k64 metadata layout for columns 0–31 for .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 type.
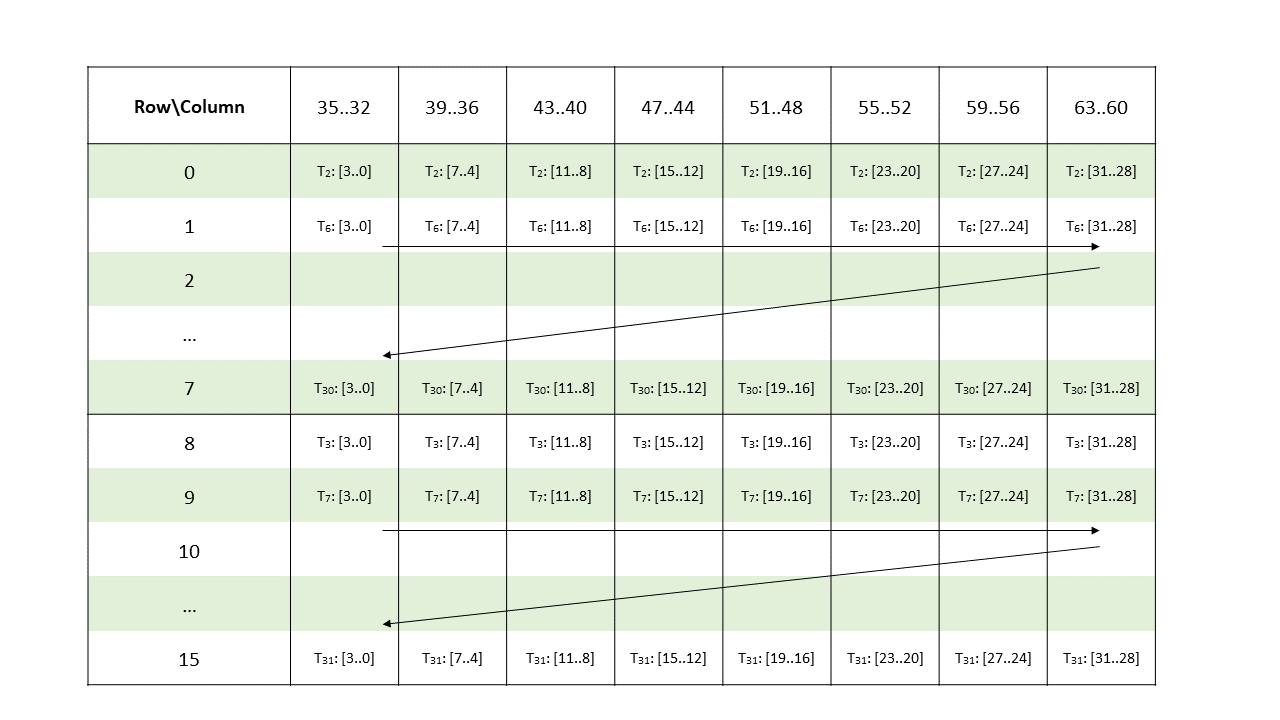
Figure 137 Sparse MMA .m16n8k64 metadata layout for columns 32–63 for .u8/.s8/.e4m3/.e5m2/.e3m2/.e2m3/.e2m1 type.
9.7.14.6.2.7. Matrix Fragments for sparse mma.m16n8k64 with .u4 / .s4 integer type
A warp executing sparse mma.m16n8k64 with .u4 / .s4 integer type will compute an MMA operation of shape .m16n8k64.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements |
|---|---|---|
.u4 / .s4 |
A vector expression containing two .b32 registers, with each register containing eight non-zero .u4 / .s4 elements out of 16 consecutive elements from matrix A. Mapping of the non-zero elements is as described in Sparse matrix storage. |
The layout of the fragments held by different threads is shown in Figure 138.
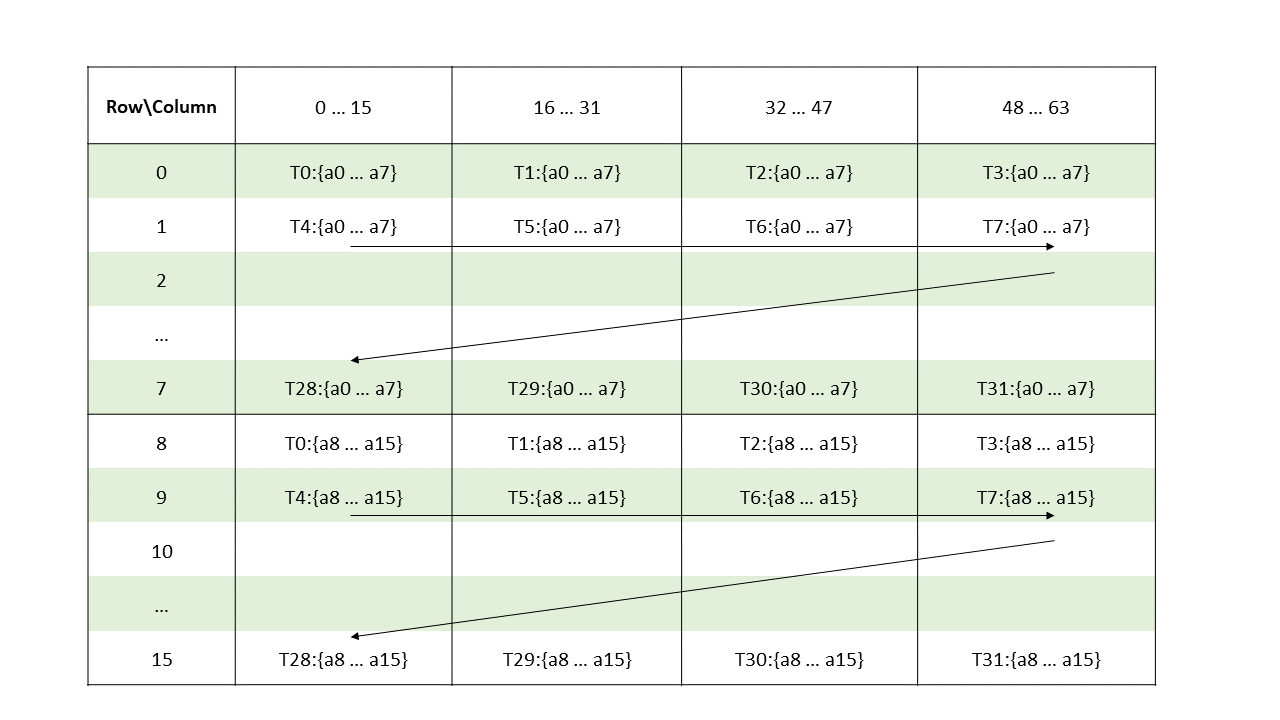
Figure 138 Sparse MMA .m16n8k64 fragment layout for matrix A with .u4/.s4 type.
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID for ai where 0 <= i < 8
groupID + 8 Otherwise
col = [firstcol ... lastcol] // As per the mapping of non-zero elements
// as described in Sparse matrix storage
Where
firstcol = threadID_in_group * 16
lastcol = firstcol + 15Matrix fragments for multiplicand B and accumulators C and D are the same as in case of Matrix Fragments for mma.m16n8k64.
Metadata: A .b32 register containing 16 2-bit vectors with each pair of 2-bit vectors storing the indices of four non-zero elements from a 8-wide chunk of matrix A as shown in Figure 139.
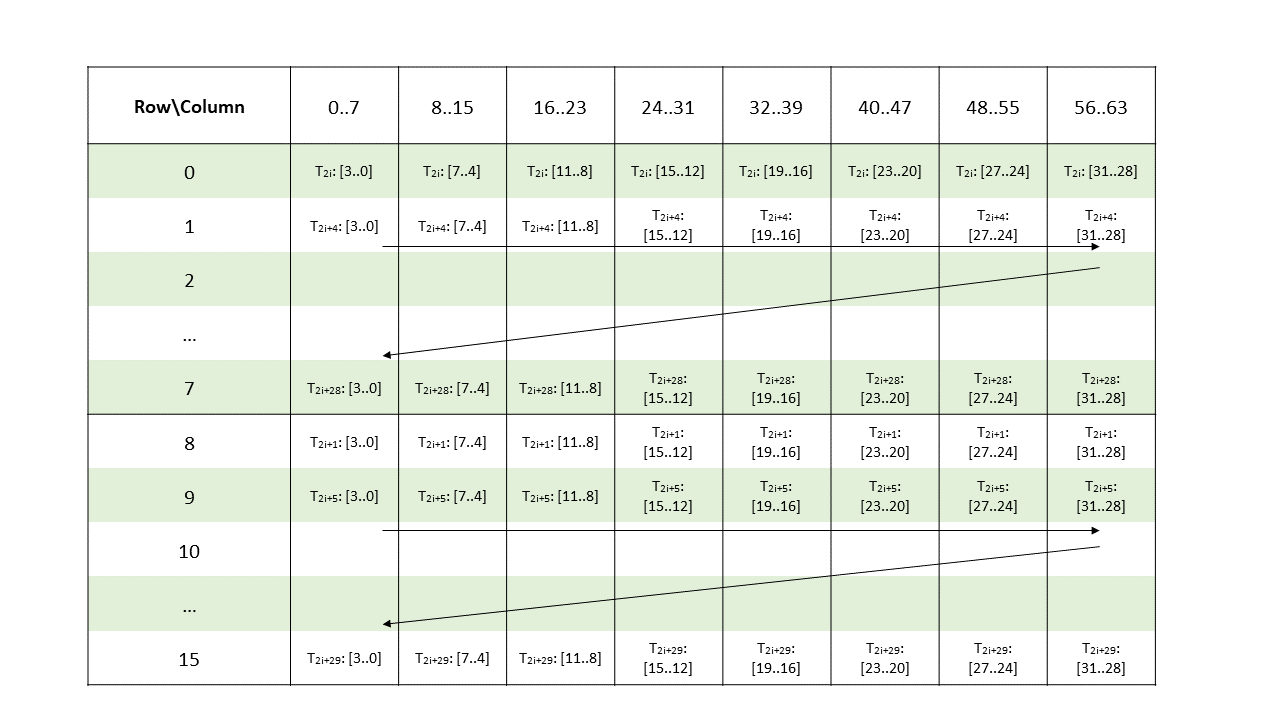
Figure 139 Sparse MMA .m16n8k64 metadata layout for .u4/.s4 type.