9.7.15.5.1. Register Fragments and Shared Memory Matrix Layouts
The input matrix A of the warpgroup wide MMA operations can be either in registers or in the shared memory. The input matrix B of the warpgroup wide MMA operations must be in the shared memory. This section describes the layouts of register fragments and shared memory expected by the warpgroup MMA instructions.
When the matrices are in shared memory, their starting addresses must be aligned to 16 bytes.
9.7.15.5.1.1. Register Fragments
This section describes the organization of various matrices located in register operands of the wgmma.mma_async instruction.
9.7.15.5.1.1.1. Matrix Fragments for wgmma.mma_async.m64nNk16
A warpgroup executing wgmma.mma_async.m64nNk16 will compute an MMA operation of shape .m64nNk16 where N is a valid n dimension as listed in Matrix Shape.
Elements of the matrix are distributed across the threads in a warpgroup so each thread of the warpgroup holds a fragment of the matrix.
Multiplicand A in registers:
.atype |
Fragment | Elements (low to high) |
|---|---|---|
.f16/.bf16 |
A vector expression containing four .f16x2 registers, with each register containing two .f16/ .bf16 elements from matrix A. |
a0, a1, a2, a3, a4, a5, a6, a7 |
The layout of the fragments held by different threads is shown in Figure 148.
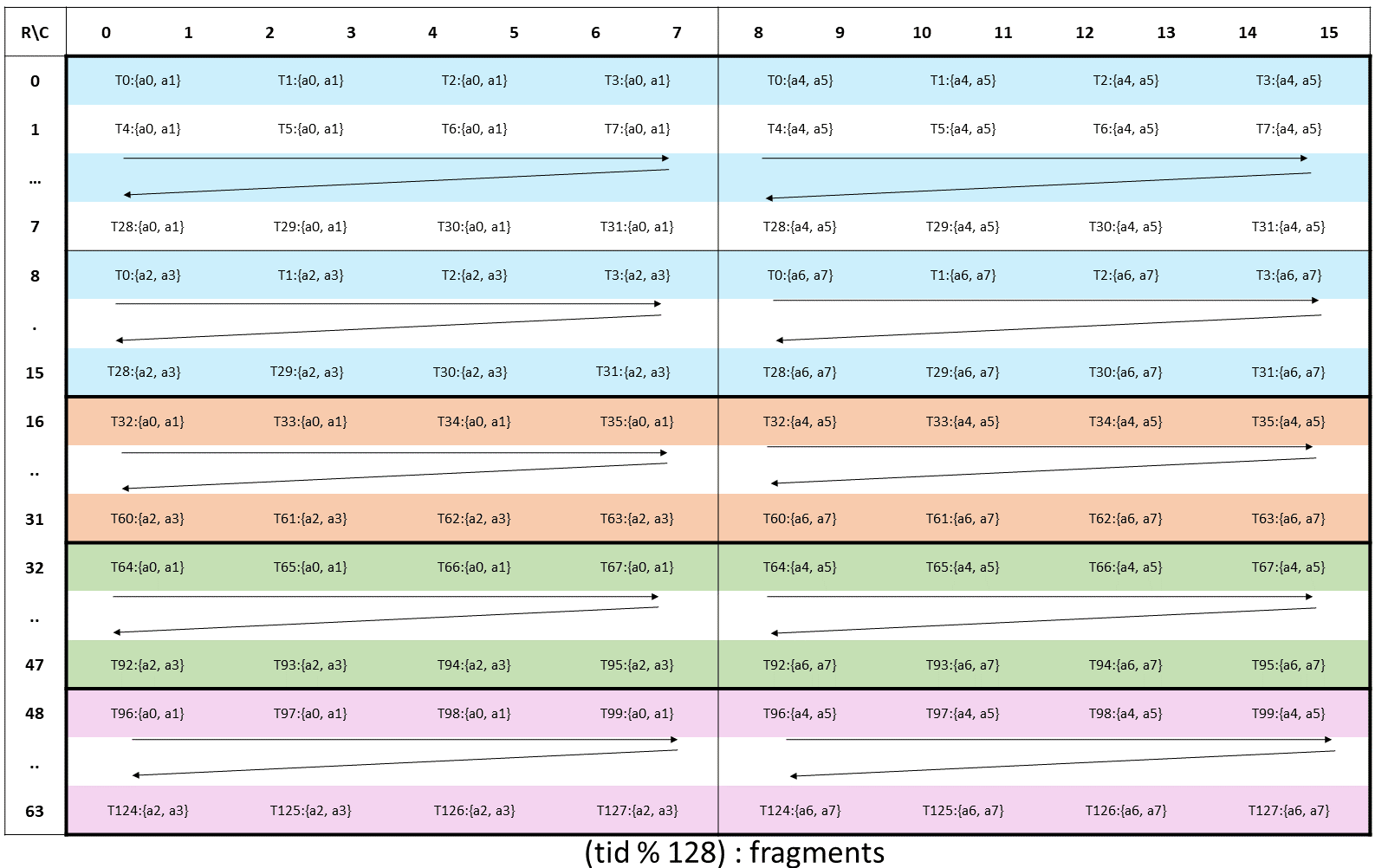
Figure 148 WGMMA .m64nNk16 register fragment layout for matrix A.
Accumulator D:
.dtype |
Fragment | Elements (low to high) |
|---|---|---|
.f16 |
A vector expression containing N/4 number of .f16x2 registers, with each register containing two .f16 elements from matrix D. |
d0, d1, d2, d3, …, dX, dY, dZ, dW<br>where X = N/2 - 4<br>Y = N/2 - 3<br>Z = N/2 - 2<br>W = N/2 - 1<br>N = 8\*i where i = {1, 2, ... , 32} |
.f32 |
A vector expression containing N/2 number of .f32 registers. |
The layout of the fragments held by different threads is shown in Figure 149.
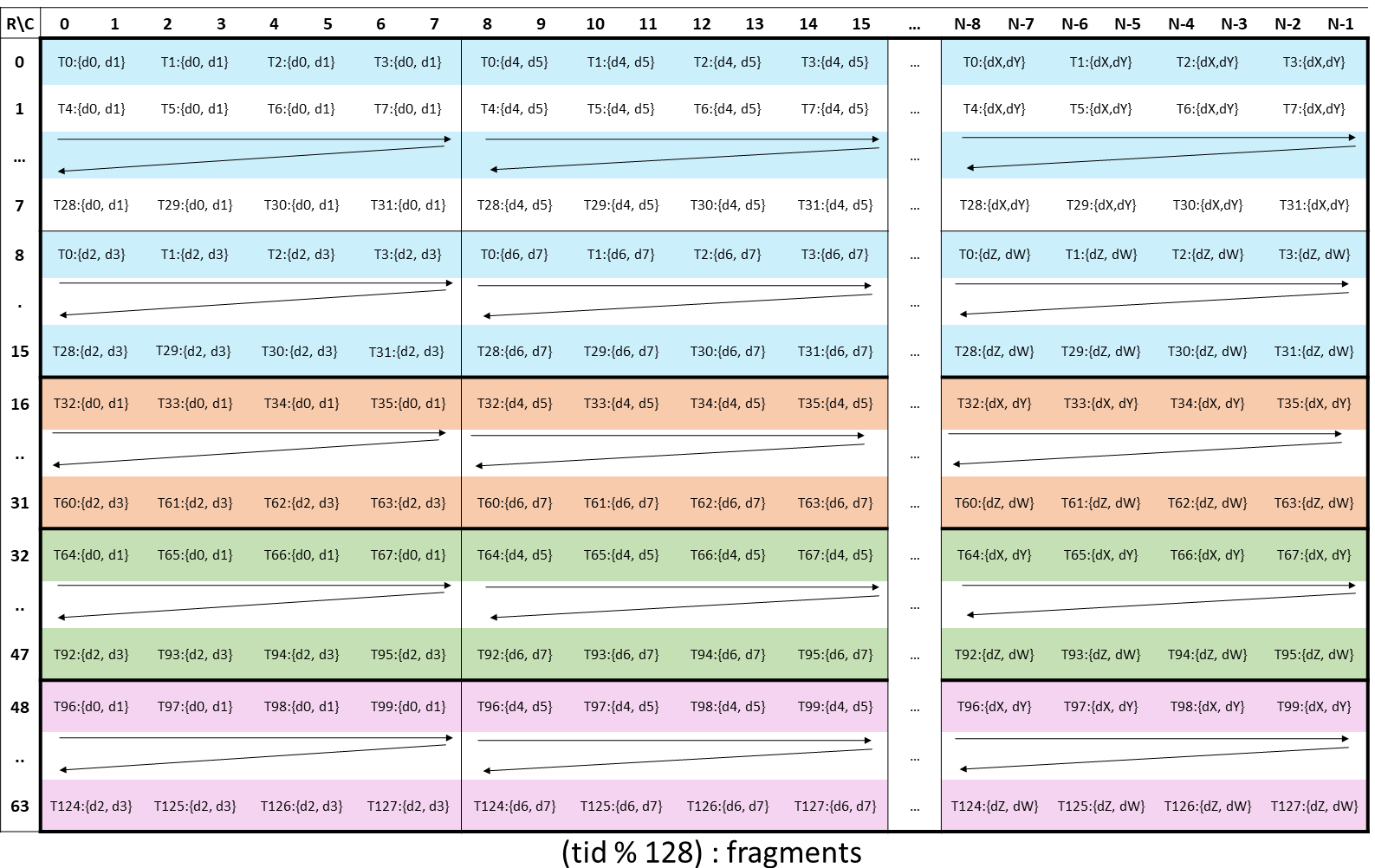
Figure 149 WGMMA .m64nNk16 register fragment layout for accumulator matrix D.
9.7.15.5.1.1.2. Matrix Fragments for wgmma.mma_async.m64nNk8
A warpgroup executing wgmma.mma_async.m64nNk8 will compute an MMA operation of shape .m64nNk8 where N is a valid n dimension as listed in Matrix Shape.
Elements of the matrix are distributed across the threads in a warpgroup so each thread of the warpgroup holds a fragment of the matrix.
Multiplicand A in registers:
.atype |
Fragment | Elements (low to high) |
|---|---|---|
.tf32 |
A vector expression containing four .b32 registers containing four .tf32 elements from matrix A. |
a0, a1, a2, a3 |
The layout of the fragments held by different threads is shown in Figure 150.

Figure 150 WGMMA .m64nNk8 register fragment layout for matrix A.
Accumulator D:
.dtype |
Fragment | Elements (low to high) |
|---|---|---|
.f32 |
A vector expression containing N/2 number of .f32 registers. |
d0, d1, d2, d3, …, dX, dY, dZ, dW<br>where X = N/2 - 4<br>Y = N/2 - 3<br>Z = N/2 - 2<br>W = N/2 - 1<br>N = 8\*i where i = {1, 2, ... , 32} |
The layout of the fragments held by different threads is shown in Figure 151.
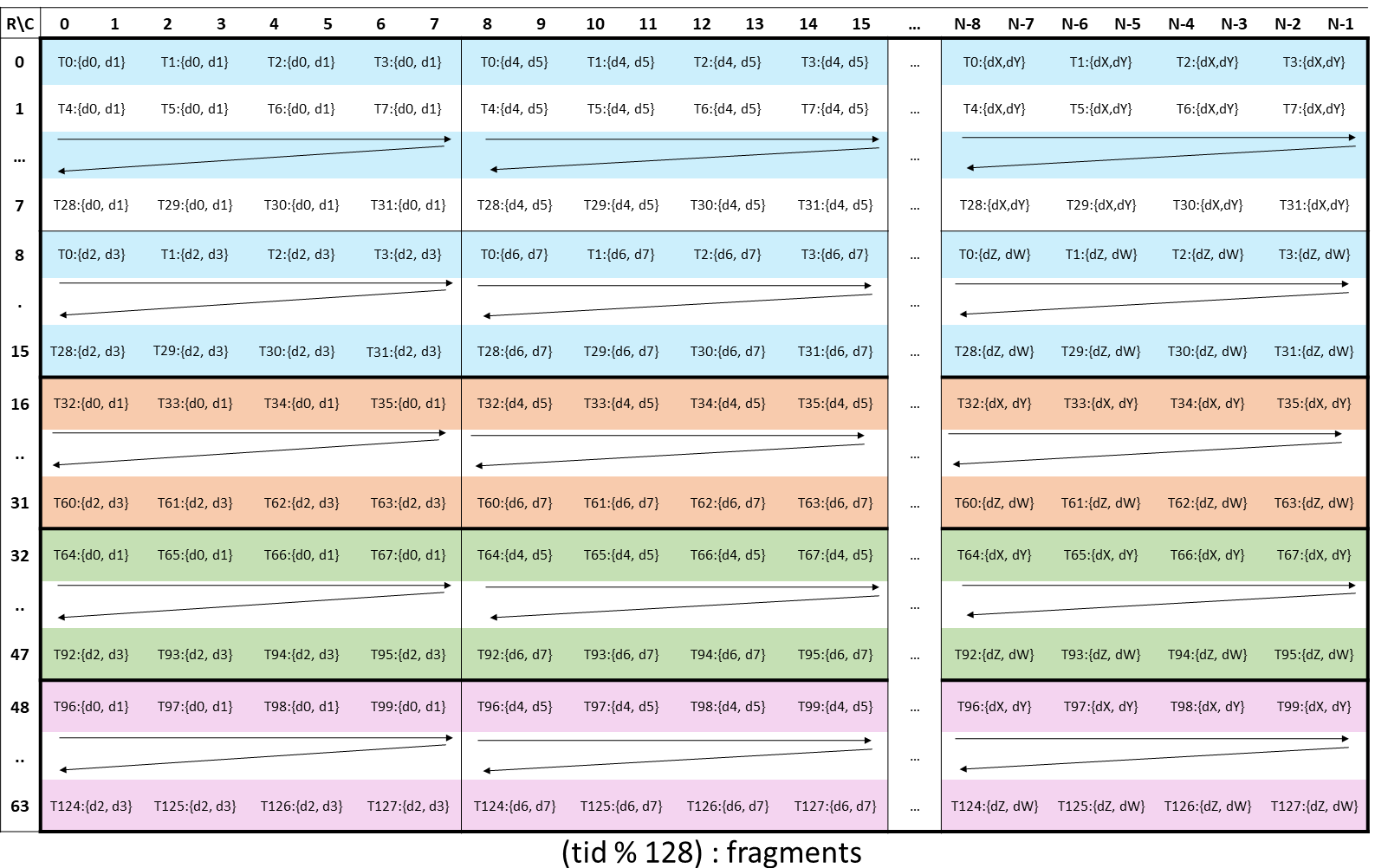
Figure 151 WGMMA .m64nNk8 register fragment layout for accumulator matrix D.
9.7.15.5.1.1.3. Matrix Fragments for wgmma.mma_async.m64nNk32
A warpgroup executing wgmma.mma_async.m64nNk32 will compute an MMA operation of shape .m64nNk32 where N is a valid n dimension as listed in Matrix Shape.
Elements of the matrix are distributed across the threads in a warpgroup so each thread of the warpgroup holds a fragment of the matrix.
Multiplicand A in registers:
.atype |
Fragment | Elements (low to high) |
|---|---|---|
.s8/.u8 |
A vector expression containing four .b32 registers, with each register containing four .u8/ .s8 elements from matrix A. |
a0, a1, a2, a3, … , a14, a15 |
.e4m3/ .e5m2 |
A vector expression containing four .b32 registers, with each register containing four .e4m3/ .e5m2 elements from matrix A. |
The layout of the fragments held by different threads is shown in Figure 152.
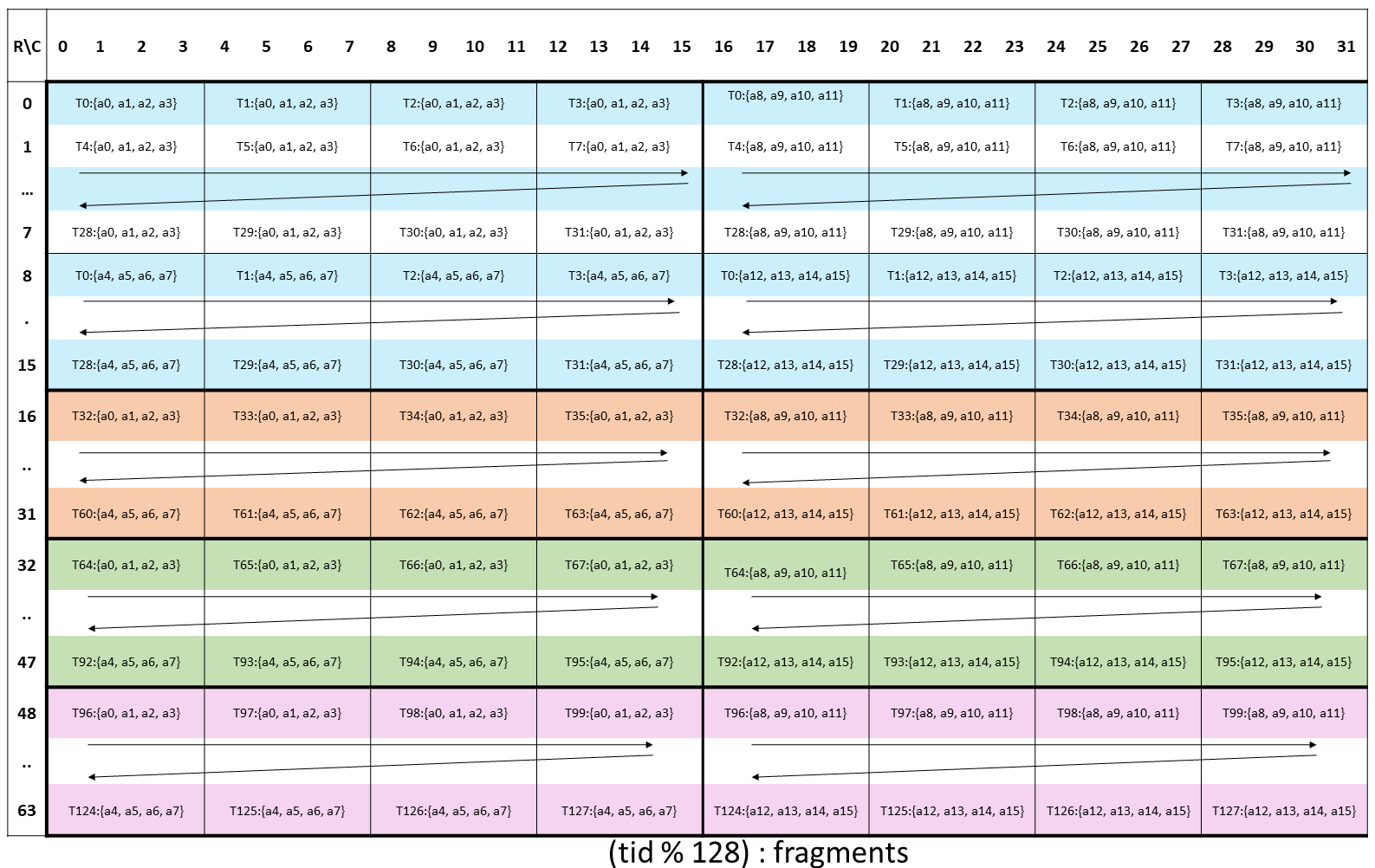
Figure 152 WGMMA .m64nNk32 register fragment layout for matrix A.
Accumulator D:
.dtype |
Fragment | Elements (low to high) | Miscellaneous Information |
|---|---|---|---|
.s32 |
A vector expression containing N/2 number of .s32 registers. |
d0, d1, d2, d3, …, dX, dY, dZ, dW<br>where X = N/2 - 4<br>Y = N/2 - 3<br>Z = N/2 - 2<br>W = N/2 - 1<br>N depends on .dtype, as described in the next column. |
N = 8\i where i = {1, 2, 3, 4}<br>= 16\i where i = {3, 4, ..., 15, 16} |
.f32 |
A vector expression containing N/2 number of .f32 registers. |
N = 8\*i where i = {1, 2, ... , 32} | |
.f16 |
A vector expression containing N/4 number of .f16x2 registers, with each register containing two .f16 elements from matrix D. |
The layout of the fragments held by different threads is shown in Figure 153.
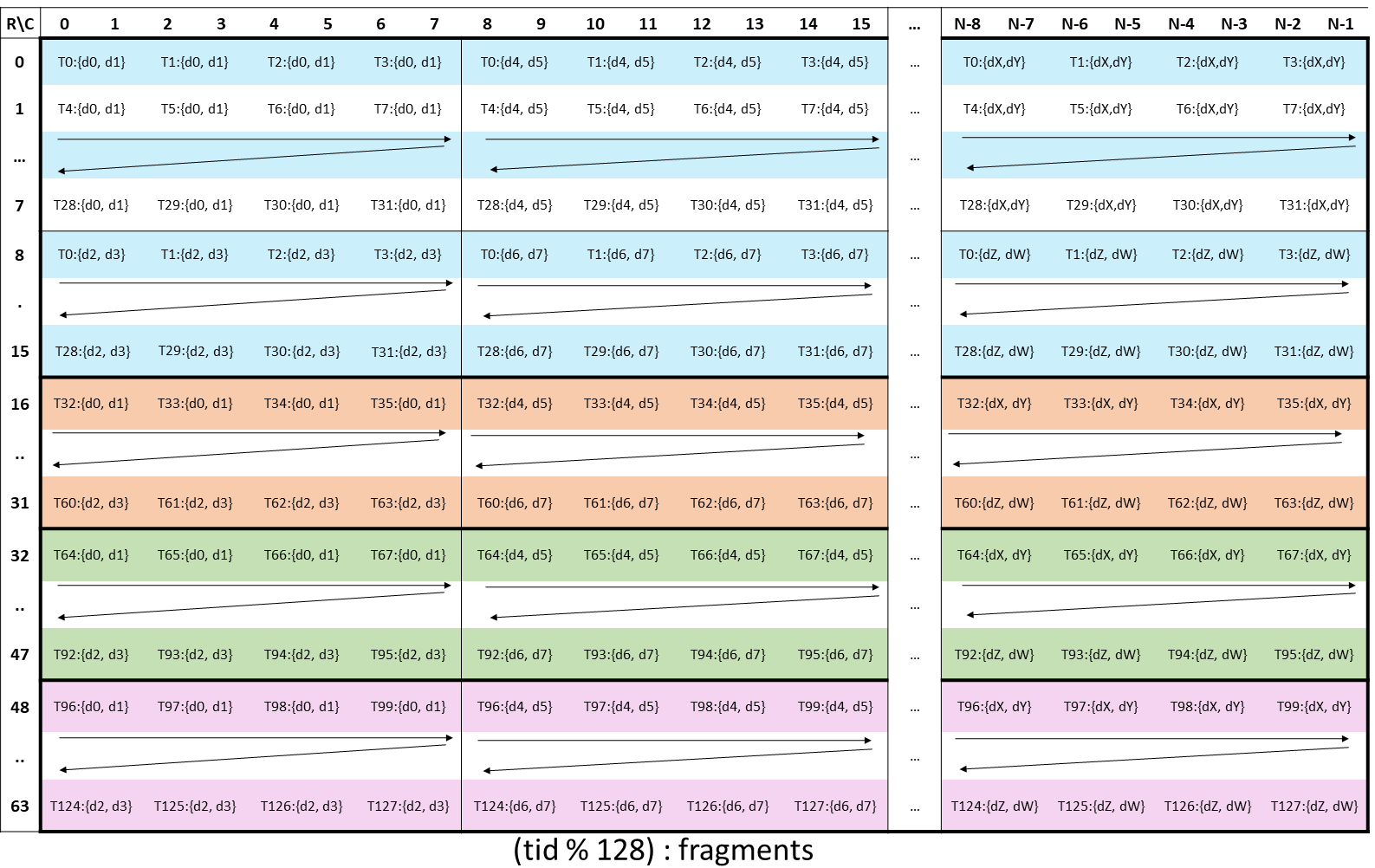
Figure 153 WGMMA .m64nNk32 register fragment layout for accumulator matrix D.
9.7.15.5.1.1.4. Matrix Fragments for wgmma.mma_async.m64nNk256
A warpgroup executing wgmma.mma_async.m64nNk256 will compute an MMA operation of shape .m64nNk256 where N is a valid n dimension as listed in Matrix Shape.
Elements of the matrix are distributed across the threads in a warpgroup so each thread of the warpgroup holds a fragment of the matrix.
Multiplicand A in registers:
.atype |
Fragment | Elements (low to high) |
|---|---|---|
.b1 |
A vector expression containing four .b32 registers, with each register containing thirty two .b1 element from matrix A. |
a0, a1, a2, …, a127 |
The layout of the fragments held by different threads is shown in Figure 154.

Figure 154 WGMMA .m64nNk256 register fragment layout for matrix A.
Accumulator D:
.dtype |
Fragment | Elements (low to high) |
|---|---|---|
.s32 |
A vector expression containing N/2 number of .s32 registers. |
d0, d1, d2, d3, …, dX, dY, dZ, dW<br>where X = N/2 - 4<br>Y = N/2 - 3<br>Z = N/2 - 2<br>W = N/2 - 1<br>N = 8\i where i = {1, 2, 3, 4}<br>= 16\i where i = {3, 4, ..., 15, 16} |
The layout of the fragments held by different threads is shown in Figure 155.

Figure 155 WGMMA .m64nNk256 register fragment layout for accumulator matrix D.