9.7.14.5.15. Warp-level matrix load instruction: ldmatrix
ldmatrix
Collectively load one or more matrices from shared memory for mma instruction
Syntax
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
ldmatrix.sync.aligned.m8n16.num{.ss}.dst_fmt.src_fmt r, [p];
ldmatrix.sync.aligned.m16n16.num.trans{.ss}.dst_fmt.src_fmt r, [p];
.shape = {.m8n8, .m16n16};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16, .b8};
.dst_fmt = { .b8x16 };
.src_fmt = { .b6x16_p32, .b4x16_p64 };Description
Collectively load one or more matrices across all threads in a warp from the location indicated by the address operand p, from .shared state space into destination register r. If no state space is provided, generic addressing is used, such that the address in p points into .shared space. If the generic address doesn't fall in .shared state space, then the behavior is undefined.
The .shape qualifier indicates the dimensions of the matrices being loaded. Each matrix element holds 16-bit or 8-bit or 6-bit or 4-bit data.
Following table shows the matrix load case for each .shape.
.shape |
Matrix shape | Element size |
|---|---|---|
.m8n8 |
8x8 | 16-bit |
.m16n16 |
16x16 | 8-bit or 6-bit or 4-bit |
.m8n16 |
8x16 | 6-bit or 4-bit |
Following table shows the valid use of 6-bit or 4-bit data load.
.src_fmt |
.shape |
Source data | Padding | .dst_fmt |
|---|---|---|---|---|
.b6x16_p32 |
.m8n16 |
16 6-bit elements | 32 bits | .b8x16 (16 8-bit elements) |
.m16n16 |
||||
.b4x16_p64 |
.m8n16 |
16 4-bit elements | 64 bits | |
.m16n16 |
For .b6x16_p32 format source data is 16 unsigned 6-bit elements with 32 bits padding. For .b4x16_p64 format source data is 16 unsigned 4-bit elements with 64 bits padding.
The values .x1, .x2 and .x4 for .num indicate one, two or four matrices respectively. When .shape is .m16n16, only .x1 and .x2 are valid values for .num.
The mandatory .sync qualifier indicates that ldmatrix causes the executing thread to wait until all threads in the warp execute the same ldmatrix instruction before resuming execution.
The mandatory .aligned qualifier indicates that all threads in the warp must execute the same ldmatrix instruction. In conditionally executed code, an ldmatrix instruction should only be used if it is known that all threads in the warp evaluate the condition identically, otherwise the behavior is undefined.
The behavior of ldmatrix is undefined if all threads do not use the same qualifiers, or if any thread in the warp has exited.
The destination operand r is a brace-enclosed vector expression consisting of 1, 2, or 4 32-bit registers as per the value of .num. Each component of the vector expression holds a fragment from the corresponding matrix.
Supported addressing modes for p are described in Addresses as Operands.
Consecutive instances of row need not be stored contiguously in memory. The eight addresses required for each matrix are provided by eight threads, depending upon the value of .num as shown in the following table. Each address corresponds to the start of a matrix row. Addresses addr0–addr7 correspond to the rows of the first matrix, addresses addr8–addr15 correspond to the rows of the second matrix, and so on.
.num |
Threads 0–7 | Threads 8–15 | Threads 16–23 | Threads 24–31 |
|---|---|---|---|---|
.x1 |
addr0–addr7 | – | – | – |
.x2 |
addr0–addr7 | addr8–addr15 | – | – |
.x4 |
addr0–addr7 | addr8–addr15 | addr16–addr23 | addr24–addr31 |
Note: For
.target sm_75or below, all threads must contain valid addresses. Otherwise, the behavior is undefined. For.num = .x1and.num = .x2, addresses contained in lower threads can be copied to higher threads to achieve the expected behavior.
When reading 8x8 matrices, a group of four consecutive threads loads 16 bytes. The matrix addresses must be naturally aligned accordingly.
Each thread in a warp loads fragments of a row, with thread 0 receiving the first fragment in its register r, and so on. A group of four threads loads an entire row of the matrix as shown in Figure 104.
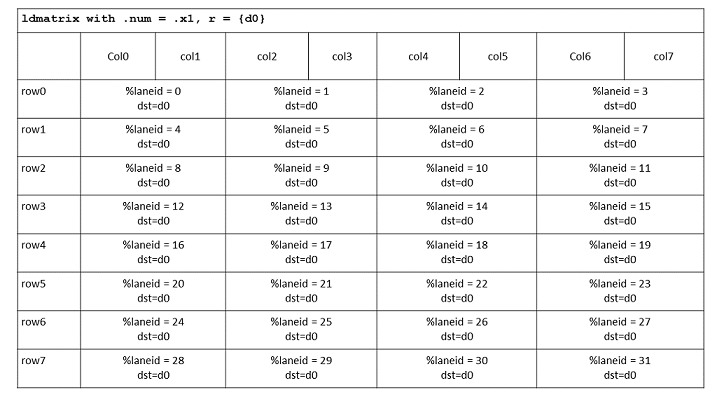
Figure 104 ldmatrix fragment layout for one 8x8 Matrix with 16-bit elements
When .num = .x2, the elements of the second matrix are loaded in the next destination register in each thread as per the layout in above table. Similarly, when .num = .x4, elements of the third and fourth matrices are loaded in the subsequent destination registers in each thread.
For matrix shape 16x16, two destination registers r0 and r1 of type .b32 must be specified and in each register four 8-bit elements are loaded. For 4-bit or 6-bit data, 8-bit element will have 4 bits or 2 bits of padding respectively. Refer Optional Decompression for more details on these formats.
An entire row of the matrix can be loaded by a group of four consecutive and aligned threads. Each thread in a warp loads 4 consecutive columns across 2 rows as shown in the Figure 105.

Figure 105 ldmatrix fragment layout for one 16x16 matrix with 8-bit elements
For matrix shape 8x16, one destination register r0 of type .b32 must be specified where four 8-bit elements are loaded in the register. For 4-bit or 6-bit data, 8-bit element will have 4 bits or 2 bits of padding respectively.
An entire row of the matrix can be loaded by a group of four consecutive and aligned threads. Each thread in a warp loads 4 consecutive columns as shown in Figure 106.

Figure 106 ldmatrix fragment layout for one 8x16 matrix with 8-bit elements containing 4-bit/6-bit data
Optional qualifier .trans indicates that the matrix is loaded in column-major format. However, for 16x16 matrices, .trans is mandatory.
The ldmatrix instruction is treated as a weak memory operation in the Memory Consistency Model.
PTX ISA Notes
Introduced in PTX ISA version 6.5.
Support for ::cta sub-qualifier introduced in PTX ISA version 7.8.
Support for .m16n16, .m8n16 shapes introduced in PTX ISA version 8.6.
Support for .b8 type with ldmatrix is introduced in PTX ISA version 8.6.
Support for .src_fmt, .dst_fmt qualifiers introduced in PTX ISA version 8.6.
Target ISA Notes
Requires sm_75 or higher.
Shapes .m16n16, .m8n16 are supported on following architectures:
sm_100asm_101a(Renamed tosm_110afrom PTX ISA version 9.0)sm_120a
And are supported on following family-specific architectures from PTX ISA version 8.8:
sm_100for higher in the same familysm_101for higher in the same family (Renamed tosm_110ffrom PTX ISA version 9.0)sm_120for higher in the same familysm_110for higher in the same family
Type .b8 with ldmatrix is supported on following architectures:
sm_100asm_101a(Renamed tosm_110afrom PTX ISA version 9.0)sm_120a
And are supported on following family-specific architectures from PTX ISA version 8.8:
sm_100for higher in the same familysm_101for higher in the same family (Renamed tosm_110ffrom PTX ISA version 9.0)sm_120for higher in the same familysm_110for higher in the same family
Qualifiers .src_fmt, .dst_fmt are supported on following architectures:
sm_100asm_101a(Renamed tosm_110afrom PTX ISA version 9.0)sm_120a
And are supported on following family-specific architectures from PTX ISA version 8.8:
sm_100for higher in the same familysm_101for higher in the same family (Renamed tosm_110ffrom PTX ISA version 9.0)sm_120for higher in the same familysm_110for higher in the same family
Examples
// Load a single 8x8 matrix using 64-bit addressing
.reg .b64 addr;
.reg .b32 d;
ldmatrix.sync.aligned.m8n8.x1.shared::cta.b16 {d}, [addr];
// Load two 8x8 matrices in column-major format
.reg .b64 addr;
.reg .b32 d<2>;
ldmatrix.sync.aligned.m8n8.x2.trans.shared.b16 {d0, d1}, [addr];
// Load four 8x8 matrices
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m8n8.x4.b16 {d0, d1, d2, d3}, [addr];
// Load one 16x16 matrices of 64-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<2>;
ldmatrix.sync.aligned.m16n16.x1.trans.shared.b8 {d0, d1}, [addr];
// Load two 16x16 matrices of 64-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m16n16.x2.trans.shared::cta.b8 {d0, d1, d2, d3}, [addr];
// Load two 16x16 matrices of 6-bit elements and transpose them
.reg .b64 addr;
.reg .b32 d<4>;
ldmatrix.sync.aligned.m16n16.x2.trans.shared::cta.b8x16.b6x16_p32 {d0, d1, d2, d3}, [addr];