9.7.14.5. Matrix Fragments for mma.m8n8k128
A warp executing mma.m8n8k128 will compute an MMA operation of shape .m8n8k128.
Elements of the matrix are distributed across the threads in a warp so each thread of the warp holds a fragment of the matrix.
Multiplicand A:
.atype |
Fragment | Elements (low to high) |
|---|---|---|
.b1 |
A vector expression containing a single .b32 register, containing thirty two .b1 elements from the matrix A. |
a0, a1, … a30, a31 |
The layout of the fragments held by different threads is shown in Figure 62.

Figure 62 MMA .m8n8k128 fragment layout for matrix A with .b1 type.
The row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID
col = (threadID_in_group * 32) + i for ai where i = {0,..,31}Multiplicand B:
.btype |
Fragment | Elements (low to high) |
|---|---|---|
.b1 |
A vector expression containing a single .b32 register, containing thirty two .b1 elements from the matrix B. |
b0, b1, …, b30, b31 |
The layout of the fragments held by different threads is shown in Figure 63.
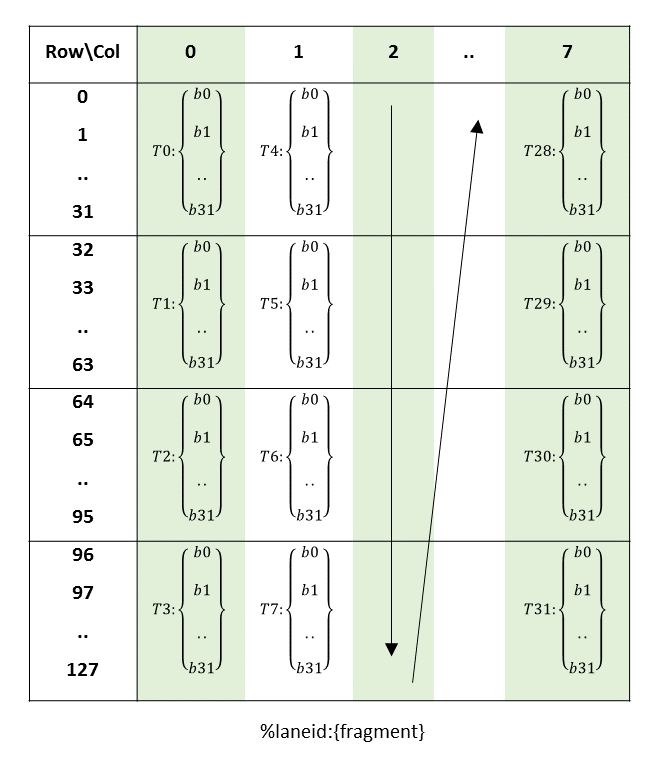
Figure 63 MMA .m8n8k128 fragment layout for matrix B with .b1 type.
The row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = (threadID_in_group * 32) + i for bi where i = {0,..,31}
col = groupIDAccumulators (C or D):
.ctype / .dtype |
Fragment | Elements (low to high) |
|---|---|---|
.s32 |
A vector expression containing two .s32 registers, containing two .s32 elements from the matrix C (or D). |
c0, c1 |
The layout of the fragments held by different threads is shown in Figure 64.
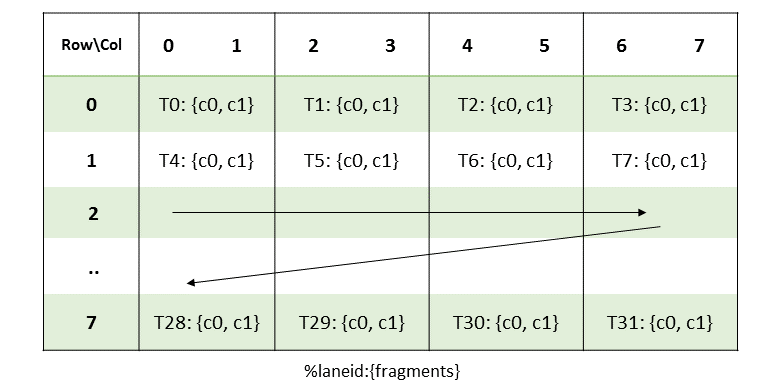
Figure 64 MMA .m8n8k128 fragment layout for accumulator matrix C/D with .s32 type
The row and column of a matrix fragment can be computed as:
groupID = %laneid >> 2
threadID_in_group = %laneid % 4
row = groupID
col = (threadID_in_group * 2) + i for ci where i = {0, 1}